Apache Nutch
Tarihçe ve Tanım
![]() Dev veriden bahsedildiğinde Hadoop’un başlangıç projesi olan Nutch’tan söz etmemek olmaz. “Hadoop nasıl başladı?” sorusunun cevabı bizi Nutch isimli Apache projesine götürür. Nutch’ın temelleri ise Google arama motoru yapmak için işe başlandığında bunun en hızlı şekilde yapabilmesi için GFS ve MapReduce teknolojilerinin yayınlaması ile atıldı. Peki Nutch için HDFS ve MapReduce neden gerekli? Bir crawlera sahipseniz büyük veriye sahipsiniz demektir. Bir çok sitenin içeriğine sahip olmak ve bunlar üzerinden kolayca işlem yapabilmek için dağıtık bir sisteme ihtiyacınız vardır; bunun da en güzel yolu HDFS ve MapReduce’dur.
Dev veriden bahsedildiğinde Hadoop’un başlangıç projesi olan Nutch’tan söz etmemek olmaz. “Hadoop nasıl başladı?” sorusunun cevabı bizi Nutch isimli Apache projesine götürür. Nutch’ın temelleri ise Google arama motoru yapmak için işe başlandığında bunun en hızlı şekilde yapabilmesi için GFS ve MapReduce teknolojilerinin yayınlaması ile atıldı. Peki Nutch için HDFS ve MapReduce neden gerekli? Bir crawlera sahipseniz büyük veriye sahipsiniz demektir. Bir çok sitenin içeriğine sahip olmak ve bunlar üzerinden kolayca işlem yapabilmek için dağıtık bir sisteme ihtiyacınız vardır; bunun da en güzel yolu HDFS ve MapReduce’dur.
Projenin nasıl çalıştırılıp ve istenilen çalışma şekline nasıl getirileceği konularında bilgi vermeye çalışacağım. Anlatımlarım linux işletim sistemi üzerinden olacaktır. İşletim sisteminize uymuyorsa veya sorun yaşıyorsanız işletim sisteminiz üzerine Virtual Machine araçları (VMWare, VirtualBox vs.) ile Ubuntu-12.04.4 kurup sıfır bir işletim sistemi ile deneyebilirsiniz.
İndirme ve Derleme
1) Öncelikle projenin kaynak kodunu Apache’nin sitesinden indirmeniz gerekmekte.
link : http://www.apache.org/dyn/closer.cgi/nutch/
Anlatımlarım apache-nutch-1.8 verisonun src’si için olacak. Projeyi indirdikten sonra bilgisayarınızda istediğiniz bir konuma zip’ten çıkartın.
2) Bilgisayarınızda JAVA_HOME ‘un ayarlı olması gerekiyor.
export JAVA_HOME=$(readlink -f /usr/bin/java | sed "s:bin/java::")
komutunu çalıştırın veya ~/.bashrc dosyanıza bu komutu ekleyin.
3) Komut satırından projenizin bulunduğu klasöre gidin
$cd apache-nutch_Xsurum/
4) $ant runtime komutunu çağırın ve projenizin bulunduğu klasörde runtime/local şeklinde bir klasör oluşmuş olması gerekiyor.
Not: ant bulunamadı hatası aldıysanız $sudo apt-get install ant komutunu çağırın ve tekrar deneyin.
Ayarlamalar için gerekli Config dosyalarıda runtime/local/conf/ klasörü altında bulunuyor. Hatırlatmakta fayda var $ant clean komutunu çalıştırmaya gerek duyduğunuzda runtime dosyası silineceğinden ant clean komutunu çalıştırmadan önce config dosyalarınızı yedekleyin.
Kontrol
Komut satırından runtime/local içinde iken $bin/nutch yazın, eğer bir sorun yoksa aşağıdaki ifadeyi görmeniz gerekmekte.
Usage: nutch COMMAND where COMMAND is one of:
readdb read / dump crawl db mergedb merge crawldb-s, with optional filtering readlinkdb read / dump link db inject inject new urls into the database generate generate new segments to fetch from crawl db freegen generate new segments to fetch from text files fetch fetch a segment's pages parse parse a segment's pages
Erişim izni hatası alırsanız $chmod +x bin/nutch kodunu çalıştırıp tekrar deneyin.
Nutch Ayarları
1) Nutch için belirlenmiş default ayarları conf/default.xml dosyasının içinde bulabilirsiniz. Buradaki ayarlardan size gereken ayarı kullanmak için ise conf/nutch-site.xml ‘e o ayarı kopyalamanız gerekmekte.
Projemizi ilk kez çalıştırmadan önce bazı ayarlar yapmamız gerekmekte.
http.agent.name property ayarı yapmak için conf/nutch-site.xml dosyamıza aşağıdaki kodu kopyalayalım ve kaydedelim.
<property> <name>http.agent.name</name> <value>My Nutch Spider</value> </property>
2) Nutch bize içeriğini çekeceğimiz siteleri belirlememiz için kolay bir yol sunmakta. Text dosyasına satırlar halinde içeriğini çekmek istediğimiz siteleri yazmamız gerekiyor. Bunun için aşağıdaki komutları çalıştırabilirsiniz veya normal yoldan runtime/local/ dosyası içine urls klasörü yaratıp içine seed.txt adında bir text file yaratıp içine satırlar halinde urlleri yazabilirsiniz.
$mkdir -p urls $cd urls $touch seed.txt
Bu komutlarla runtime/local/urls/seed.txt adında bir dosya yaratmış olduk içine içeriğini istediğiniz sitelerin urllerini yazmanız gerekiyor. Urllerin başlarında http:// olmasına dikkat edin yoksa hata alabilirsiniz. Örnek olarak http://devveri.com/ yazıp kaydediyoruz.
3) İsterseniz sitenin içinde istediğiniz şekilde bir veri alımı için regex yazabilirsiniz. Bunu yapmak için conf/regex-urlfilter.txt dosyasını açıp en alt kısımdaki;
# accept anything else +.
yerine
+^http://([a-z0-9]*\.)*devveri.com/
yazabilirsiniz. Bu regex programınızın sadece site içinde bulduğu linklerden sitenin dışına çıkan linklerin içeriğine gitmeme faydası sağlar. Bu kısmı böyle bir dosyanın var olduğunu bilmeniz için anlattım +. şeklinde kalabilir.
Solr Ayarları
Anlatımımda çektiğiniz içerikler direk solra indexlenecektir.Bunun için localinizdeki solr ın schema.xml’ini ayarlamamnız gerekmekte. Nutch’ın Solr 4.3.0 ile sorunsuz çalıştığı söylenmekte bunun için localinizdeki Solr’ın bu versiyon olduğunu kabul edip anlatımıma devam ediyorum. Eğer mevcut değilse derlenmiş Solr 4.3.0’ı indirmeniz grekmekte. Derlenmiş 4.3.0 İndirmek için link :
http://archive.apache.org/dist/lucene/solr/4.3.0/
Nutch dosyanızdaki conf/schema-solr4.xml dosyasını Solr ın bulunduğu klasördeki schema.xml ile değiştirmeniz gerekiyor. Öncelikle solrın bulunduğu klasördeki schema.xml dosyanızın ismini schema.xml.org olarak değiştirip sonrasında yerine conf/schema-solr4.xml dosyasını kopyalayıp ismini schema.xml olarak değiştirmenizi tavsiye ederim.
Sonrasında değiştridiğiniz yeni schema.xml ‘in 351. satırına
<field name="_version_" type="long" indexed="true" stored="true"/>
ifadesini ekleyiniz.
Solr’ı yeni bir komut penceresinde çalıştırın.
$java -jar start.jar
Nutch Akış Şeması
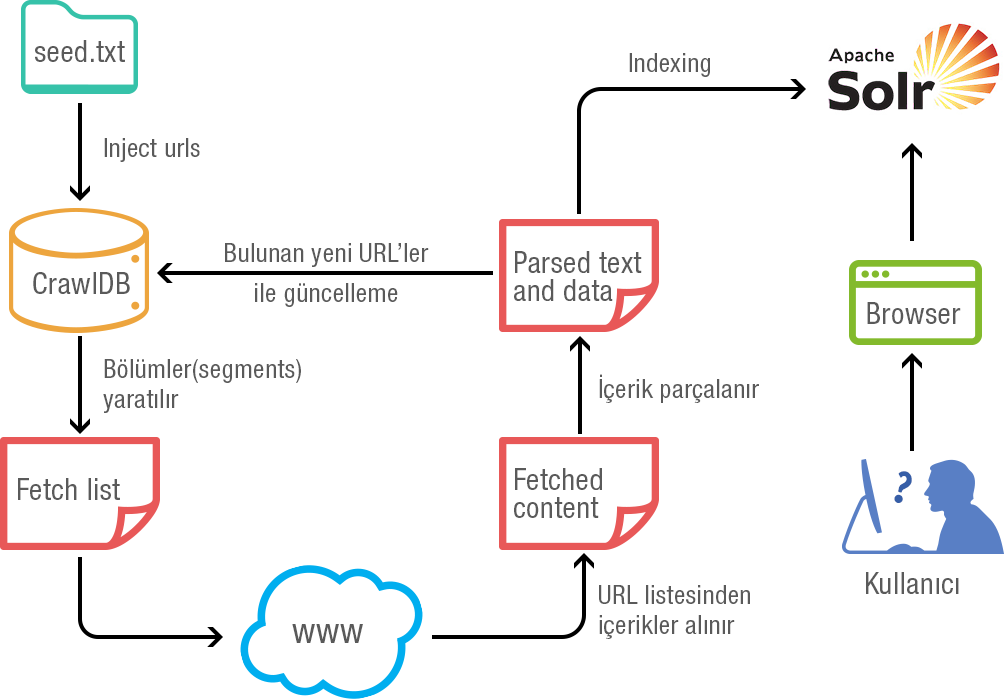 Proje urls/seed.txt içerisinde tanımladığınız url’leri crawldb ‘ye koyar ve MapReduce çalıştırarak koyduğunuz sitenin içeriğini çekmeye başlar. Yukarıda ki şemada görülen döngünün sayısını siz verdiğiniz parametre ile belirlersiniz. Her döngü sonunda index güncellenir ve solr paremetre olarak verildiyse ilk döngü bittiğinde solr’ın panelinden ilk indexlerin geldiğini görebilirsiniz.
Proje urls/seed.txt içerisinde tanımladığınız url’leri crawldb ‘ye koyar ve MapReduce çalıştırarak koyduğunuz sitenin içeriğini çekmeye başlar. Yukarıda ki şemada görülen döngünün sayısını siz verdiğiniz parametre ile belirlersiniz. Her döngü sonunda index güncellenir ve solr paremetre olarak verildiyse ilk döngü bittiğinde solr’ın panelinden ilk indexlerin geldiğini görebilirsiniz.
Crawl Komutu ile Çalıştırma
1) Artık projemizi belirlediğiniz sitenin içeriğini almak için çalıştırabiliriz.
$bin/crawl urls/seed.txt testcrawl http://localhost:8983/solr/ 2
Buradaki 2 değerini döngü sayısı gibi düşünebilirsiniz. Elinizde başlangıçta anasayfa url var.İlk döngüde anasayfanın içeriğini alır ve bulduğu linkleride ikinci döngüye hazırlar. İkinci döngüde birinciden gelen yeni urllerin içeriklerini alır ve bulduğu urlleri diğer döngüye hazırlar. 2 dersek proje burada durur. Aynı şekilde tekrar çalıştırdığımızda son kaldığı yerden 2 döngü daha atarak ilerler. 2 sayısının yerine bir seferde kaç döngüde çalışmasını istiyorsanız yazabilirsiniz.
2) Komutu çalıştırdığınızda MapReduce’un işlediğini göreceksiniz ve işlem bittiğinde aşağıdaki gibi yaratılmış bir dosya düzenine sahip olacaksınız.
testcrawl/crawldb testcrawl/linkdb testcrawl/segments
Nutch Komutu ile Çalıştırma
Projenizi $bin/nutch komutu ilede çalıştırabilirsiniz ama önerilmeyen bir çalışma biçimidir.
$bin/nutch crawl urls -dir crawl -depth 3 -topN 5
Komutunu çalıştırın
** depth anasayfadan ne kadar derine ineceğini gösterir.
Örnek : Anasayfada 111.html linki var bu sayfada 222.html linki var vs
Kısaca anasayfadan başlayıp her bulduğu linkinde içeriğini alıp onların götürdüğü linklerin içeriğinide alacakmı ne kadar derine gidecek depth onun ayarlanması içindir.
**topN ise her derinlikte maximum ne kadar url in yeni içerik alma listesine ekleneceğinin ayarıdır.
$bin/nutch crawl2 urls -solr http://localhost:8983/solr/ -depth 3 -topN 5
Not: crawl2 yazmamın sebebi solr olmadağan çalıştırdığımız komut crawl dosyası içinde veriler yaratmıştı ikinci kez crawl yazarsak ilk crawlda bulduğu veriler üzerinden devam eder.
Faydalı Bilgiler
*runtime/deploy klasörüde dikkatinizi çekmiştir. Eğer aynı komutları burada çalıştırmak isterseniz. urls klasörünün hdfs te olması gerekiyor. Ve sonuç crawl dosyanız hdfs e yazılır.
* nutch-site.xml den nasıl faydalanabileceğiniz konusunda birkaç örnek vereyim.
—Yazının başında yazdığımız regex in yaptığı iş için böyle bir ayar mevcut crawl işlemi esnasında value true ise sitenin dışına çıkmadan crawl işlemini gerçekleştirmeye yarıyor.
<property> <name>db.ignore.external.links</name> <value>false</value> <description>If true, outlinks leading from a page to external hosts will be ignored. This is an effective way to limit the crawl to include only initially injected hosts, without creating complex URLFilters. </description> </property>
—Aynı sunucuya atılan ardışık isteklerdeki bekleme süresi
<property> <name>fetcher.server.delay</name> <value>5.0</value> <description>The number of seconds the fetcher will delay between successive requests to the same server.</description> </property>
*Nutch crawl surecinin adimlarını merak ediyorsanız daha detaylı bilgi için
http://wiki.apache.org/nutch/NutchTutorial inceleyebilirsiniz.