1win, Spor ve Gazino oyunları için yenilikçi bir web sitesidir ve oyun keyfiniz için temiz ve modern bir arayüz sunar. Mükemmel bir canlı bahis bölümü, çok çeşitli ödeme yöntemleri ve gelişmiş güvenlik sistemi ile site binlerce Türk kullanıcısına kaliteli hizmet sunmaktadır.
Web sitesi, Curaçao tarafından verilen uluslararası bir lisans altında faaliyet göstermekte ve 1win yasal olup olmadığını merak ediyorsanız, Türkiyedeki operasyonların yasallığını sağlamaktadır. Minimum 50 TRY para yatırma ile web sitesini keşfetmeye başlayın. Ayrıca, daha fazla bilgi için aşağıdaki tabloyu kontrol edin:
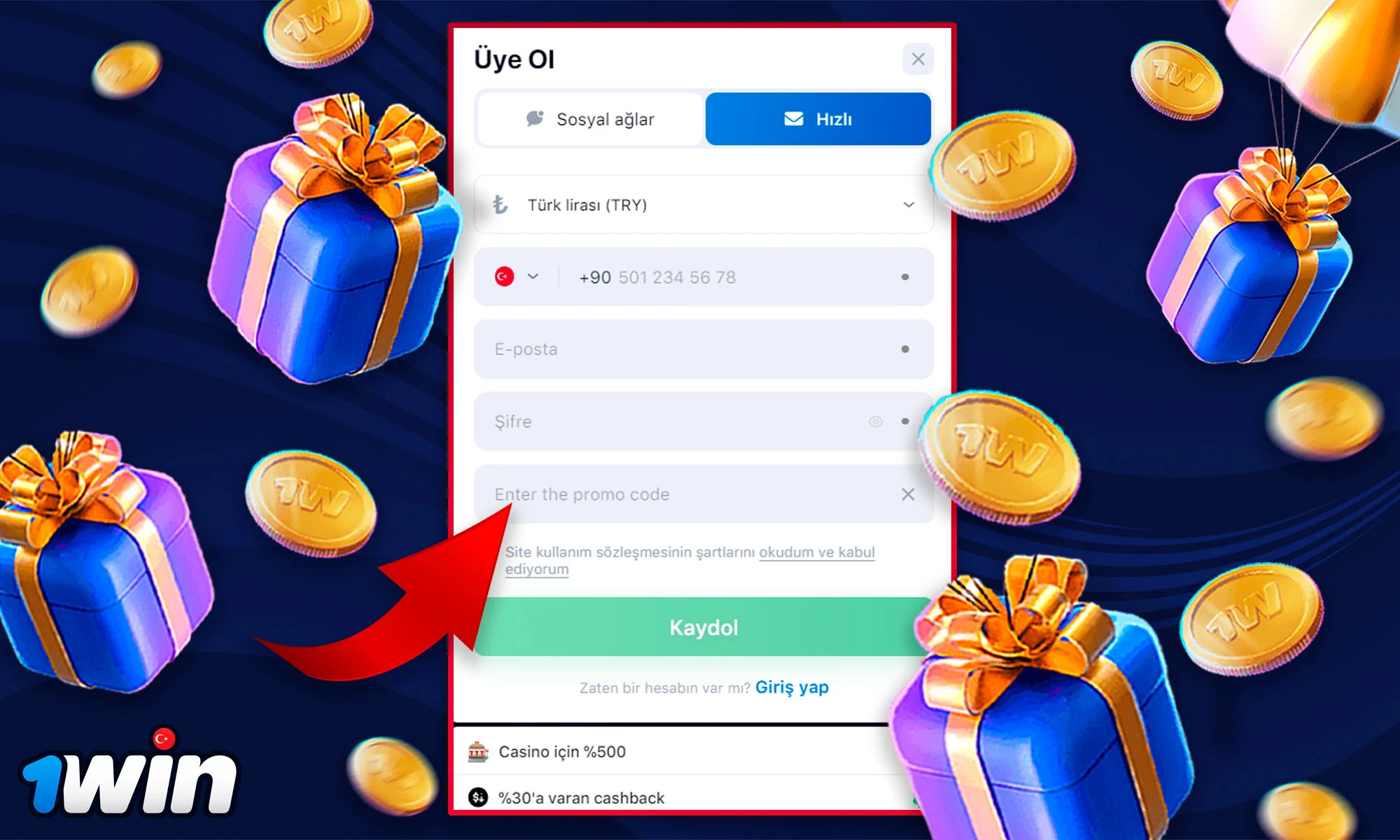
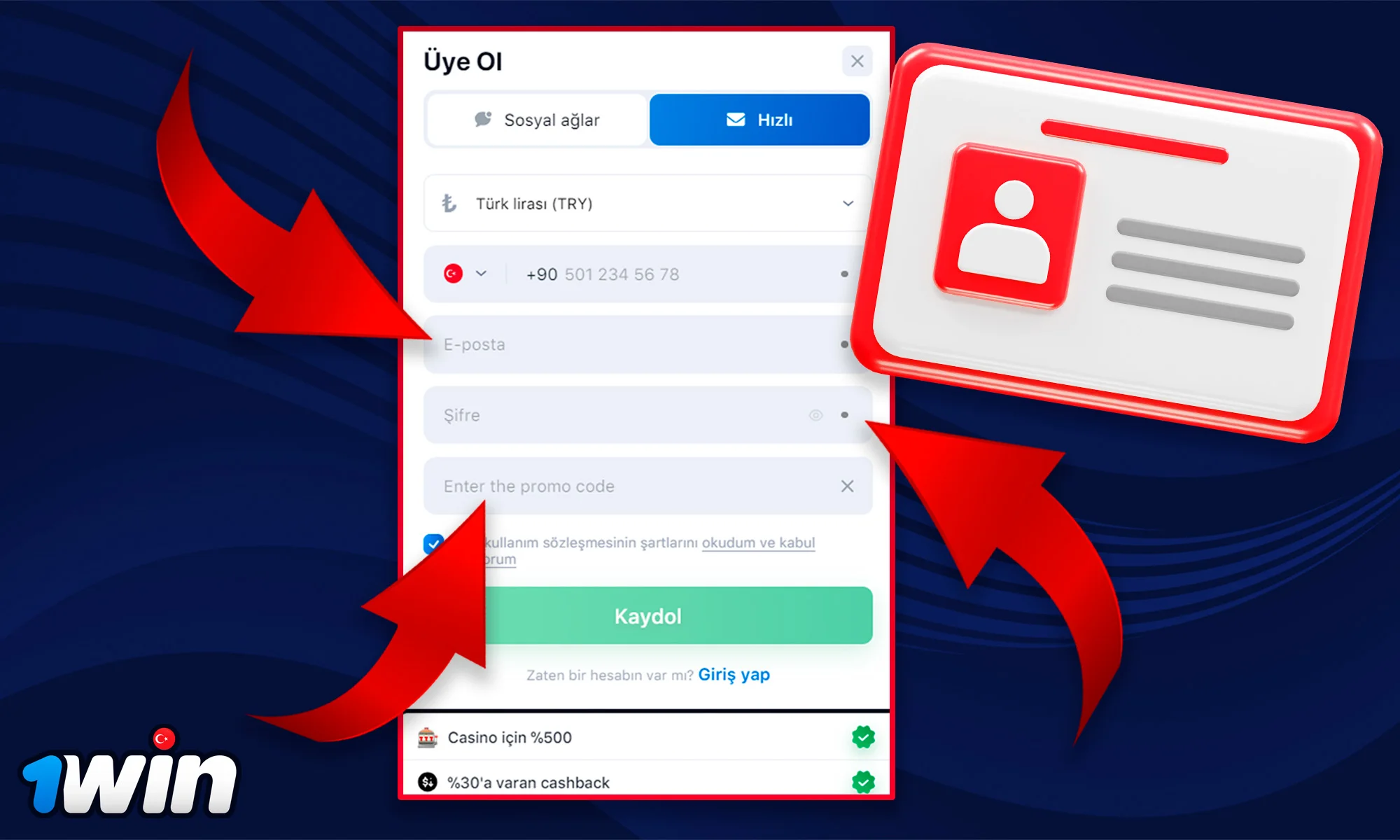
Kayıt olmak