Cloudera Impala: Hadoop üzerinde Gerçek Zamanlı Sorgulama
Hadoop üzerindeki verileri SQL arayüzü ile analiz etmek amacıyla Hive projesi yaygın bir şekilde kullanılıyor. Hive ile yazılan SQL sorguları Hadoop mimarisinde dağıtık bir şekilde çalıştırılmak amacıyla MapReduce kodlarına çevriliyor. Bu sayede klasik RDBMS’lerin çoğunun cevap dahi veremeyeceği sorgular Hive ile kısa bir zamanda tamamlanabiliyor. Örneğin sağlam bir donanıma da sahip olsa tek bir MySQL sunucusu üzerinde 5 dk süren bir sorgu, Hive ile 40 sn gibi bir sürede tamamlanabiliyor. Ancak Hive, daha ziyade veri ambarı işleri ve büyük miktardaki veri üzerinde kullanılma amacıyla tasarlandığı için, anlık olarak sorgulara cevap verme gibi bir özelliği bulunmuyor.
Ancak günümüzde anlık olarak verilerin işlenmesi ihtiyacı giderek artıyor, dolayısı ile Hadoop’un da bu konuda bir cevaba ihtiyacı var. Bu ihtiyacı ilk olarak görerek bu konuda çalışmaları yapan her zaman olduğu gibi tabiiki Google. 2010 yılında yayınladıkları Dremel makalesinde kendi altyapılarında bu ihtiyaçları nasıl karşıladıklarını anlatıyorlar. Bu makeleden faydalanan birçok ticari ve açık kaynaklı proje bulunuyor.
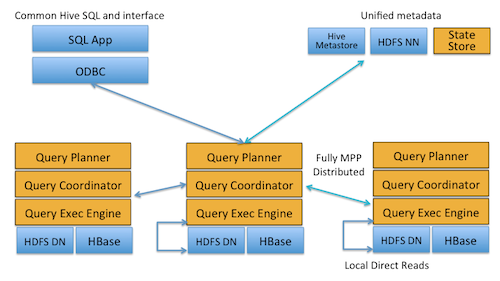
Cloudera tarafından geliştirilen açık kaynaklı Impala, bu projelerden bir tanesi. HDFS veya HBase üzerindeki veriler, SELECT, JOIN ve aggregation fonksiyonları ile gerçek zamanlı sorgulanabiliyor. Impala’nın en önemli avantajlarından birisi de Hive ile aynı SQL arayüzünü, sürücüleri ve ortak metadata’yı kullanabilmesi. Impala da Hive gibi text, sequence, avro, rcfile vb. birçok farklı dosya formatını destekliyor.
Impala çalışma mantığını “Dağıtık SQL Sorgulama Motoru” olarak tanımlayabiliriz. Hive’dan farklı olarak Impala sorguları MapReduce işlerine çevrilmez. Bu sayede MapReduce işlerinin başlatılması, koordine edilmesi, gerektiğinde tekrar çalıştırılması gibi zaman alan işlevlerden arınır. Bunun yerine dağıtık sorgular aracılığı ile, verilere direkt erişir. Sorgulama motoru verilen sorguyu analiz ederek dağıtık olarak nasıl çalıştırılacağını hesaplar, sonrasında her düğüm üzerinde gerekli sorguları çalıştırır. Sorguların sonrasında her düğümden alınan sonuçlar HDFS üzerinde değil direkt olarak hafıza üzerinde birleştirilir. Birleştirilme işlemi hafıza üzerinde yapıldığından dolayı daha hızlı çalışır fakat bunun için sistemde yeterli hafıza olması gerekir. Bu işlemler sırasında Parquet adı verilen daha işlevsel ve performanslı bir format kullanılıyor.
Performans açısından Impala ile Hive karşılaştırıldığında;
- Impala sistem kaynaklarını Hive’dan daha efektif bir şekilde kullanır. Bu sayede bir performans kazancı sağlanır.
- Hive’da birden fazla MapReduce işi ile yapılması gereken ya da Reduce Side Join yöntemi gerektiren sorgularda Impala öne çıkar. Benzer bir performans kazancı join yapılan sorgular için de geçerli.
- Basit aggregation sorgularında Impala daha fazla cache ve hafıza kullandığı için çok daha hızlı çalışır.
Performans olarak Impala gerçekten şaşırtıcı derecede hızlı. Yazının başında bahsettiğim, Hive’da 40 sn süren bir sorgu Impala ile gerçekten 1 saniyenin altında cevaplanıyor. Hatta o kadar hızlı çalışıyor ki, ilk anda sorgunun gerçekten çalışıp çalışmadığını kontrol etmek zorunda hissediyorsunuz. Her sorgu için bu durum geçerli değil elbette, ancak performansı net bir şekilde gözdolduruyor diyebilirim, en azından denediğim kadarıyla.
Impala işlev olarak Hive’a benzese de aslında Hive’ın yerini almayı amaçlamıyor. Hive çok daha uzun sürecek, çok büyük miktarda veri işlemek vs gibi durumlarda kullanılmaya devam edilirken, Impala gerçek zamanlı analitik sorgularında kullanılmaya müsait.
Öteyandan Impala’dan da gerçek bir RDBMS’den beklenen sorgu kabiliyetlerinin tamamını beklemek Hadoop mimarisi ve felsefesinden dolayı doğru değil. Ayrıca Impala şu anda beta olduğu için başka bazı eksiklikleri de bulunuyor. Bunlardan birisi kullanıcı tanımlı fonksiyonları (UDF) desteklememesi ve özellikle text formatındaki verileri işlerken yaşanabilen problemler.
Impala bu konudaki ihtiyacı karşılamaya çalışan tek proje değil. Hortonworks tarafından geliştirilen Stinger projesi ve Facebook tarafından geliştirilen Presto projeleri de aynı amaca hizmet ediyor.
Daha fazla bilgi için Cloudera sitesini ziyaret edebilirsiniz.
Hadoop 2.0 – YARN Data Scientist kimdir?