Amazon EMR ile Spark
Bu yazıda Amazon EMR üzerinde bir Spark uygulamasının nasıl çalıştırabileceğinden bahsedeceğim. Eğer EMR ile ilgili bir önceki yazıyı okumadıysanız bu yazıyı, AWS Big Data teknolojileri ile ilgili genel bilgi için de bu yazıyı okuyabilirsiniz.

EMR üzerinde çalıştıracağımız örnek uygulamada daha önce defalarca kullandığım NYSE verisini kullanacağım. Tab karakterleri ile ayrılmış bu dosya içerisinde günlük borsa işlemleri ile ilgili veriler bulunuyor. Spark 2.x ile birlikte gelen CSV desteği ile kolayca DataFrame haline getireceğimiz veriyi, S3 üzerinden okuyup üzerinde aggregation yapan bir SQL komutu çalıştırıp sonucu Parquet formatında tekrar S3 üzerine yazacağız.
Başlamadan önce işleyeceğimiz dosyayı indirip S3 üzerine atmamız gerekiyor. Bu işlemi elle AWS S3 arayüzünden yapabileceğiniz gibi komut satırından da yapabilirsiniz. Bunun için awscli uygulamasının yüklenmiş, ayarlarını yapmış olmanız ve S3 üzerindeki bucket’ı yaratmış olmanız gerekiyor.
wget https://s3.amazonaws.com/hw-sandbox/tutorial1/NYSE-2000-2001.tsv.gz aws s3 cp NYSE-2000-2001.tsv.gz s3://datapyro-main/test/
EMR içerisinde kaynak yönetimi için YARN kullandığından Spark uygulamasında master parametresini “yarn” olarak belirtmek gerekiyor. Uygulamamız input parametresi ile S3 üzerinde okuyacağı veriyi, output parametresi ile de S3 üzerinde sonucun yazılacağı yeri alıyor.
Spark ile CSV dosyaları DataFrame olarak okumak için aşağıdaki satırlar yeterli:
val df = spark.read
.option("sep", "\t")
.option("header", "true")
.csv(input)
Burada “sep” parametresi ile CSV dosyasının tab ile ayrılmış olduğunu belirtiyoruz, “header” parametresi de “true” olarak belirtildiğinde dosya içerisindeki ilk satır “header” olarak kabul ediliyor ve şemada kolon isimleri olarak kullanılıyor. Kodun tamamı şu şekilde; (Github linki üzerinden de görebilirsiniz)
package com.datapyro.emr.spark
import org.apache.spark.sql.SparkSession
object SparkS3BinaryData extends App {
// check args
if (args.length != 2) {
println("Invalid usage! You should provide input and output folders!")
System.exit(-1)
}
val input = args(0)
val output = args(1)
// initialize context
val sparkMaster: Option[String] = Option(System.getProperty("spark.master"))
val spark = SparkSession.builder
.master(sparkMaster.getOrElse("yarn"))
.appName(getClass.getSimpleName)
.getOrCreate()
// load csv as a data frame
val df = spark.read
.option("sep", "\t")
.option("header", "true")
.csv(input)
df.createOrReplaceTempView("nyse")
df.printSchema()
// execute sql
val sql =
"""
SELECT
stock_symbol,
date,
AVG(stock_price_open) AS avg_stock_price_open,
SUM(stock_volume) AS total_stock_volume
FROM nyse
GROUP BY
stock_symbol,
date
"""
val result = spark.sql(sql)
// save results as parquet
result.write
.mode("overwrite")
.option("compression", "gzip")
.parquet(output)
}
Kodu hazırladıktan sonra EMR üzerinde çalıştırabilmek için “fat JAR” dediğimiz, yani gerekli olacak tüm kütüphaneleri içeren bir JAR olarak derlemek gerekiyor. Ben maven kullandığım için projeyi buna göre konfigüre ettim, “mvn clean package -Pmake-jar” diyerek derliyorum ve sonucunda *-dist.jar uzantılı büyük bir JAR dosyası oluşuyor. Oluşan bu JAR dosyasını da S3 üzerine yüklememiz gerekiyor.
aws s3 cp target/aws-emr-examples-1.0.0-SNAPSHOT-dist.jar s3://datapyro-main/lib/
İşleyeceğimiz veriyi ve kodu hazırladıktan sonra sıra EMR üzerinde çalıştırmaya geldi. EMR kümesini AWS yönetim arayüzünden ayağa kaldırabileceğiniz gibi aynı işlemi komut satırından, SDK üzerinden ya da EMR API ile de yapabileceğinizi unutmayın.
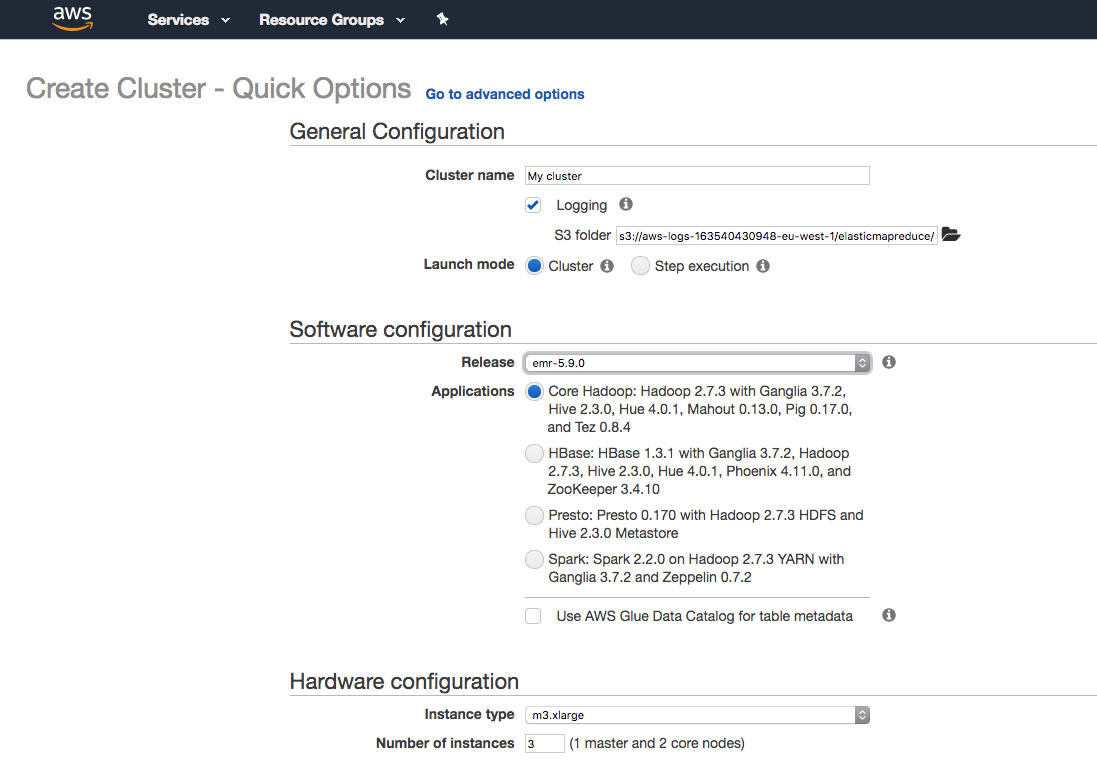
“Create Cluster” seçeneğinden sonra nasıl bir küme oluşturacağımızı ayarladığımız ekran geliyor. Bu ekranda “Cluster Name” ile kümemize bir isim veriyoruz. “Logging” seçeneğini aktif hale getirdiğimizde kümedenin log dosyaları S3 üzerinde belirtilen yere yazılıyorlar.
Launch mode “Cluster” seçildiğinde küme ayağa kalkıyor ve siz kapatana kadar (long running cluster) çalışmaya devam ediyor. “Step execution” seçeneğinde ise çalışacak görev adımlarını tanımlayabiliyorsunuz. Küme bu görevler tamamlandıktan sonra kendiliğinden kapanıyor (transient cluster).
“Software configuration” bölümünde “Release” seçeneği ile önceden konfigüre edilmiş büyük veri araçlarını içeren sürümlerden birisini seçiyoruz.Örnek kodumuz Spark 2.2.0 ile çalıştığı için buna uygun olan emr-5.9.0 sürümünü ve “Application” kısmından da “Spark: Spark 2.2.0 on Hadoop 2.7.3 YARN with Ganglia 3.7.2 and Zeppelin 0.7.2” seçeneğini seçiyoruz. Bunun yerine “Go to advanced options” kısmından gelişmiş seçeneklere geçip, tek tek yüklenecek uygulamaları seçmeniz mümkün. Unutmadan, ne kadar çok uygulama seçerseniz kümenin BOOTSTRAP aşaması da o kadar uzun sürecektir.
“Hardware configuration” bölümünde ise kümeyi oluşturacak sunucuların kapasitelerini belirliyoruz. Tekrar hatırlatmak gerekirse, aslında EMR altyapı olarak diğer birçok AWS servisinde olduğu gibi EC2’yu kullanıyor. “Number of instances” kısmından ise küme içerisinde kaç adet sunucu olacağını seçiyoruz. Bu değeri 3 olarak belirlediğinizde 1 master, 2 core sunucu oluyor.
Master sunucu sayısını değiştiremiyoruz, her zaman 1 oluyor. Bu sebeple master sunucunun problem yaşaması durumunda küme tamamen kapanıyor. Fakat core ve task sunucuları auto scaling group’lar altında ayağa kalktıkları için herhangi birinde bir sorun olması durumunda yenisi ile değiştiriliyor.
EMR üzerinde birden fazla kümeye sahip olabilirsiniz. Buradaki limit hesabınızın EC2 sunucu limitiyle sınırlıdır. Normalde 20 olan (sunucu tipine göre değişen) bu sayıyı talep edip arttırdığınızda EMR kümesinde kullanabileceğiniz sunucu sayısı da artmış oluyor.
Bir diğer not da, EMR kümesi içerisindeki sunucular tek bir Availability Zone (AZ) içerisinde bulunuyorlar. Bu sayede sunucuların birbiri arasındaki haberleşmelerinden kaynaklı ağ üzerinde yavaşlık sözkonusu olmuyor.
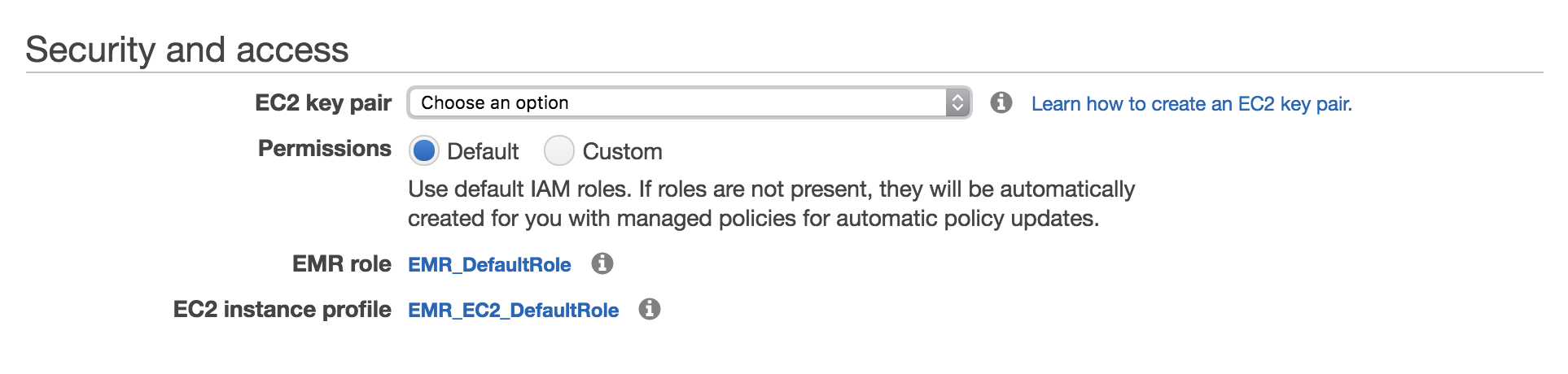
En alttaki “Security and access” kısmında ise kümedeki sunucuların güvenlik ve rol ayarları yapılıyor. “EC2 key pair” alanından daha önce tanımlı olan KP’lerden birisi seçilirse bu KP’ler ile sunuculara SSH üzerinden erişilebilir. “Permissions” kısmından “Custom” değeri seçildiğinde sunuculara tanımlanacak “EMR role” ve “EC2 instance profile” bilgileri özelleştirilebilir. “Default” değeri seçildiğinde ise “EMR_DefaultRole” ve “EMR_EC2_DefaultRole” kullanılır. Bu roller üzerinde daha sonra düzenlemeler yapabilirsiniz.
“Launch Cluster” dedikten sonra kümenin ayağa kalkmasını bekliyoruz.
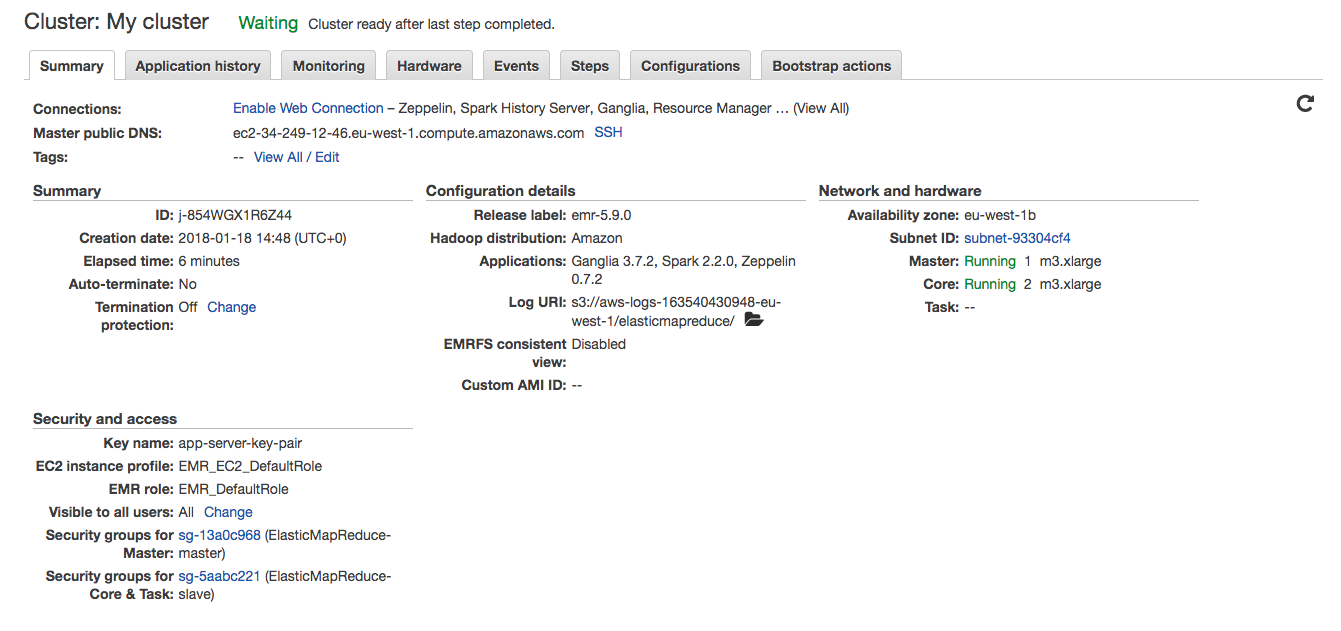
Küme hazır olduğunda “security groups” üzerinden gerekli ayarları da yaptıysanız EMR üzerinde kurulu gelen uygulamaların arayüzlerine girebilirsiniz. Örneğin master sunucunun 50070 portundan HDFS arayüzüne bakabilirsiniz:
Zeppelin de 8890 portundan aktif olarak ayağa kalkmış görünüyor:
Artık Spark uygulamamızı da çalıştırabiliriz. Uygulamayı arayüzden de çalıştırabilirdik ancak ben uygulamayı komut satırından çalıştıracağım. Bunun için ufak bir script hazırladım:
#!/bin/bash CLUSTER_ID="j-854WGX1R6Z44" CLASS_NAME="com.datapyro.emr.spark.SparkS3BinaryData" JAR_LOCATION="s3://datapyro-main/lib/aws-emr-examples-1.0.0-SNAPSHOT-dist.jar" INPUT_FOLDER="s3://datapyro-main/test" OUTPUT_FOLDER="s3://datapyro-main/output" aws emr add-steps --cluster-id $CLUSTER_ID --steps Type=spark,Name=EmrExample,Args=[--deploy-mode,cluster,--class,$CLASS_NAME,--master,yarn,--conf,spark.yarn.submit.waitAppCompletion=false,$JAR_LOCATION,$INPUT_FOLDER,$OUTPUT_FOLDER],ActionOnFailure=CONTINUE
Oluşan kümeye bir cluster_id atanıyor. Bu değeri arayüzden summary kısmında görebilirsiniz. Diğer parametreler çalışacak uygulamanın sınıf ismi, JAR dosyasının nerede olduğu, hangi klasördeki verilerin işleneceği ve nereye yazılacağı şeklinde. Ardından aws emr add-steps komutuyla diğer parametreleri geçiyoruz.
Komutu çalıştırdığımızda bu sefer yarattığımız görev adımına ait bir step_id değeri bize geri dönüyor. Bu sayede çalıştırdığımız uygulamanın durumunu da yine konsoldan takip edebiliyoruz:
$ aws emr describe-step --cluster-id $CLUSTER_ID --step-id s-CK2QM0DYXS84
{
"Step": {
"Status": {
"Timeline": {
"EndDateTime": 1516287841.679,
"CreationDateTime": 1516287792.541,
"StartDateTime": 1516287823.568
},
"State": "COMPLETED",
"StateChangeReason": {}
},
"Config": {
"Args": [
"spark-submit",
"--deploy-mode",
"cluster",
"--class",
"com.datapyro.emr.spark.SparkS3BinaryData",
"--master",
"yarn",
"--conf",
"spark.yarn.submit.waitAppCompletion=false",
"s3://datapyro-main/lib/aws-emr-examples-1.0.0-SNAPSHOT-dist.jar",
"s3://datapyro-main/test",
"s3://datapyro-main/output"
],
"Jar": "command-runner.jar",
"Properties": {}
},
"Id": "s-CK2QM0DYXS84",
"ActionOnFailure": "CONTINUE",
"Name": "EmrExample"
}
}
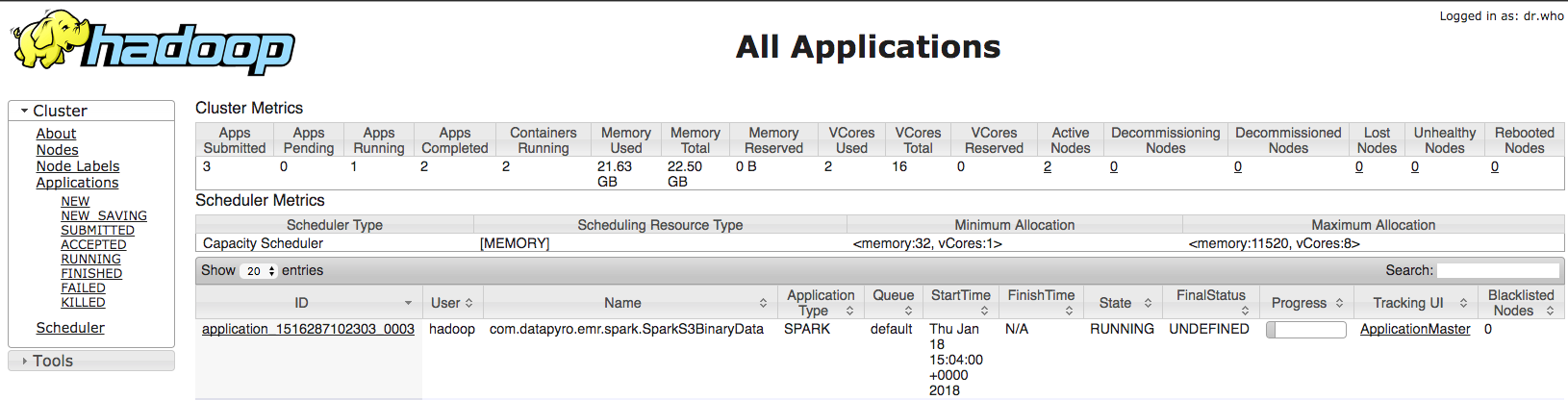
Uygulamanın çalıştığını YARN arayüzünden de görebilirsiniz:
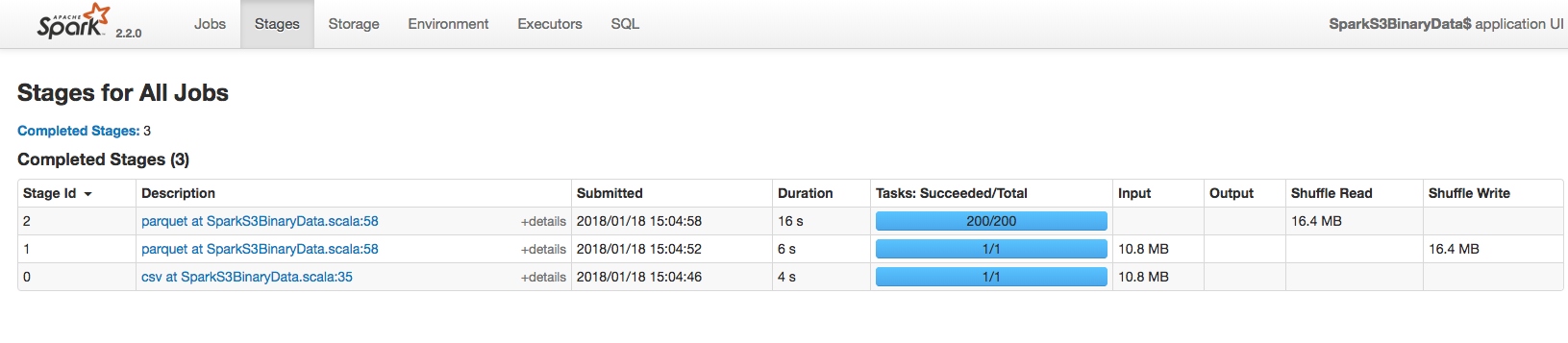
Ayrıca Spark UI üzerinden de takip edebilirsiniz:
Uygulamamız başarıyla çalıştıktan sonra S3 üzerinde output dizinine oluşan parquet dosyaların yazıldığını görebilirsiniz:
İşimiz tamamlandığında “Terminate Cluster” diyerek kümeyi kapatıyoruz. Yine daha bahsettiğim gibi bu işlemlerin hepsini komut satırından da yapmak mümkün.
Gördüğünüz üzere dakikalar içerisinde üzerinde Spark, Zeppelin gibi uygulamaların da kurulu olduğu bir Hadoop kümesi ayağa kaldırdık, veri işleyip kümeyi kapattık. Bu açıdan EMR’ın inanılmaz faydalı bir servis olduğunu söyleyebiliriz.
Başka örnek kodlara da buradan ulaşabilirsiniz: https://aws.amazon.com/articles/?tag=articles%23keywords%23elastic-mapreduce
Değerli yazınız için çok teşekkürler. Bitirme tezim için ilgileniyorum fakat 1 yıldır içerik yazmamışsınız üzücü bir durum hocam lütfen aramıza geri dönün 🙂