Apache Kafka
![]()
Günümüzde dev veri dediğimiz şey, artık her an(real-time) oluşabilen bir veri haline geldi. Her an her yerden gelen anlık veri bile devasa boyutlara ulaştı. Bunları hızlı , sorunsuz ve ölçeklenebilir bir şekilde nasıl tutarız ve bu veriye real time a yakın bir sürede nasıl tekrar ulaşabiliriz sorusu gündemi işgal etmeye başladı. Apache Kafka’da aslında bu soruya cevap olacak nitelikte bir çözüm olarak Linkedin bünyesinde geliştirildi ve daha sonra açık kaynak kodlu olarak herkesin hizmetine sunuldu.
Apache Kafka temelde log kaydına benzer bir yapıda kayıtları tutan ve bu kayıtları diğer sistemlere mesajlaşma kuyruğu(messaging queue – MQ ) şeklinde sunan bir yapıdır. Yüksek performansı ve düşük gecikme zamanı(latency) ile gerçek zamanlı veri akışı sağlar.
Temel Kavramlar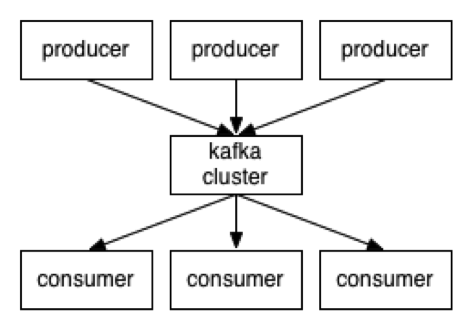
Şimdi Kafka’ya özgü kavramlara gelelim.
- Kafka mesajları “topic”lerde tutar.
- “Topic”lere mesaj gönderenler “producer”lardır.
- “Topic”leri okuyanlar ise “consumer”lardır.
- Kafka’nın çalıştığı her bir sunucu ise “broker”dır.
- “Broker”ların hepsi birlikte bir “cluster” oluşturur.
Sunucular ve istemciler arası haberleşme tamamen dil bağımsız bir TCP protokolü üzerinde olur. Bu sayede bilinen çoğu popüler dilde istemci kütüphaneleri mevcuttur.
Topic Nedir?
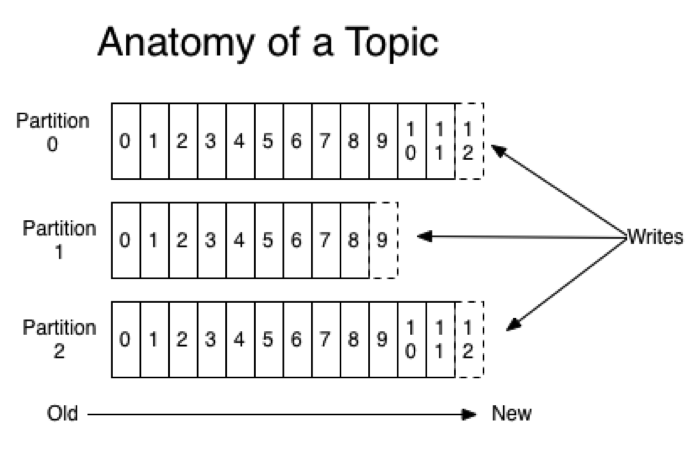
Şimdi birazda Kafka’da topic denince aslında ne kasdediliyor, bu konuyu açalım. Kafka’ya gelen mesajların tutulduğu yer bir topic ve her zaman bir ismi var. Temelde her topic bölümlendirilmiş (partitioned) bir ya da birden fazla log dosyasından oluşuyor. Her bir bölüm(partition) mevcut topicin bir kısmına sahip oluyor. Her bölüm kendi içinde bir sıra ihtiva ediyor. Bu sıraya “offset” deniyor ve her bölümde şekildende görüleceği üzere bağımsız bir offset sırası oluyor.
Topice gelen her yeni mesaj bölüm sonuna ekleniyor ve offset numarası birer birer artıyor. Bir kere bir bölüme yazılan bir mesajın offset ve partition bilgisi değişmiyor. Bütün mesajlar yapılan ayara (config) göre belirtilen süre boyunca offset bilgi değişimeden tutuluyor. Yani digger mesajlaşma sistemleri gibi okunan mesajlar artık okunamaz hale gelmiyor. (Aslında onunda bir yöntemi var, ileride anlatacağım ) Bölümlendirme sayesinde yatayda gayet rahat bir şekilde ölçeklenebilir topicler oluşturabiliyorsunuz.
Dağıtık Topic Mimarisi
Bölümlendirme sayesinde her bölüme okuma yazma işlem performansı broker sayısı ile artar hale geliyor. Çünkü Kafka’ya bağlanan her istemci, ayrı bölüme mesaj yazabiliyor ya da ayrı bölümden okuyabiliyor. Gerçek anlamda paralel okuma ve yazma işlemleri bu sayede mümkün oluyor.
Her bölüm istendiği takdirde (ayrıca tavsiye edilen) clusterdaki diğer brokerlara yedekleme amaçlı kopyalanabiliyor (replication). Her bölümün sadece bir brokerda lideri (leader) oluyor ve okuma yazma işlemleri lider bölüme yapılıyor. Diğerleri ise köle (slave) bölümler oluyorlar ve dışardan asla yazma ya da okuma işlemi yapılamıyor. Herhangi bir brokerda bir bölüm işlevsiz hale geldiğinde, o bölümün diğer kopyalardan biri o bölüm için lider olup, hizmet verir hale geliyor. Aynı topicte her bölüm için farklı makinalar lider olduğu içinde gayet dengeli bir dağılım oluyor.
Producer Kullanımı
Producer hangi mesajın ilgili topicte hangi bölüme gideceğine karar verebiliyor. Bunu ya round-robin şeklinde ya da mantıksal bölümlendirme (semantic partitioning) ile yapıyor. Bir topice mesaj gönderirken eğer bir anahtar(message key) verirseniz ve ilgili topicin mantıksal bölümlendirme fonksiyonu varsa, mesaj ona gore bir partitiona yazılır. Örneğin, gönderidğin mesajlarda anahtar olarak şehir plaka kodu gönderirseniz, aynı şehirden gelen mesajlar aynı bölümde toplanır. Kafka bu konuda garanti verir.
Consumer Kullanımı
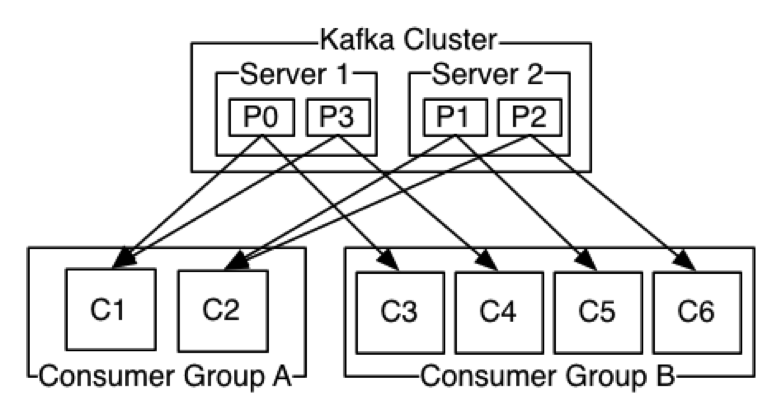 Kafka’da “consumer group” diye bir kavram vardır. Aslında her consumer bir “consumer group”a aittir. Bu consumer gruba eğer tek consumer group bağlı ise o zaman mesajları okuma şekli kuyruk (queue) davranışı sergiler. O consumer group için gelen mesajlar bütün bölümlerden tek tek okunur. Birden fazla consumerın bir consumer gruba bağlı olması durumda ise o zaman publish/subscribe denilen yapıda bir topic olur (Kafka’daki topic ile karıştırmayın J) Yani gelen mesajları birden fazla consumer group içindeki birden fazla proses birden fazla bölümden okur.
Kafka’da “consumer group” diye bir kavram vardır. Aslında her consumer bir “consumer group”a aittir. Bu consumer gruba eğer tek consumer group bağlı ise o zaman mesajları okuma şekli kuyruk (queue) davranışı sergiler. O consumer group için gelen mesajlar bütün bölümlerden tek tek okunur. Birden fazla consumerın bir consumer gruba bağlı olması durumda ise o zaman publish/subscribe denilen yapıda bir topic olur (Kafka’daki topic ile karıştırmayın J) Yani gelen mesajları birden fazla consumer group içindeki birden fazla proses birden fazla bölümden okur.
Her iki durum içinde aynı consumer group içindeki consumer sayısı bölüm sayısına eşit olursa, gerçekten hızlı bir şekilde paralel mesaj okumalar gerçekleşir. Consumer sayısını bölüm sayısından fazla verseniz bile Kafka en fazla bir consumer group içinde bölüm sayısı kadar consumerın okuma yapmasına izin verir.
Kafka her bölüm için yazma sırasında okuma sırası garantisi verir. Böylece bölüm bazlı sıralama korunmuş olur.
Komut Satırından Kullanım
İlk olarak Kafka’yı http://kafka.apache.org/downloads.html adresinden indiriyoruz. Ben bundan sonra, yazıyı yazdığım sırada en güncel sürüm 0.8.2.1 olan ile devam edeceğim.
$ tar -xzf kafka_2.10-0.8.2.1.tgz $ cd kafka_2.10-0.8.2.1
Kafka’nın dağıtık çalışması Zookeeper sayesinde oluyor. İlk olarak kendi içinde gelen Zookeeper’ı ayağa kaldırıyoruz.
$ bin/zookeeper-server-start.sh config/zookeeper.properties [2015-08-03 21:45:56,155] INFO Reading configuration from: config/zookeeper.properties (org.apache.zookeeper.server.quorum.QuorumPeerConfig)...
Zookeeper başarılı bir şekilde ayağa kalktıktan sonra, Kafka’yı ayağa kaldıralım
$ bin/kafka-server-start.sh config/server.properties [2015-08-03 21:47:04,021] INFO Verifying properties (kafka.utils.VerifiableProperties) [2015-08-03 21:47:04,049] INFO Property broker.id is overridden to 0 (kafka.utils.VerifiableProperties)...
Kafka’da her bir “topic” birden fazla parça(partition) şeklinde tutulabilir. Ayrıca fail-over senaryoları için de yedekleri (replication) tutulabilir. Şimdi bir “topic” oluşturalım.
$ bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test Created topic "test".
Oluşturduğumuz “topic”i kontrol edelim
$ bin/kafka-topics.sh --list --zookeeper localhost:2181 test
Artık yeni oluşturduğumuz bu “topic”e mesaj gönderebiliriz
$ bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test [2015-08-03 21:50:37,377] WARN Property topic is not valid (kafka.utils.VerifiableProperties) First message Second message Third message
Son olarakta oluşturduğumuz bu “topic”e gelen mesajları okuyalım
$ bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginning First message Second message Third message
Gördüğünüz gibi çok kolay bir şekilde deneme amaçlı bir topic oluşturup, bu topic e okuma yazma işlemleri yaptık. Kafka’nın asıl gücü dağıtık çalışmasında, şimdi birden fazla sunucu ayağa kaldırıp, önceden yaptığımız işlemleri bir daha yapalım.Mevcutta zaten ayakta olan bir Kafka sunucusu vardı, buna 2 tane daha sunucu ekleyelim.
İlk olarak mevcut ayar dosyasının 2 kopyasını alalım
$ cp config/server.properties config/server-1.properties $ cp config/server.properties config/server-2.properties
Bu dosyalarda aşağıdaki değişiklikleri yapalım
config/server-1.properties:
broker.id=1 port=9093 log.dir=/tmp/kafka-logs-1
config/server-2.properties:
broker.id=2 port=9094 log.dir=/tmp/kafka-logs-2
Diğer 2 sunucuyu da ayağa kaldıralım.
$ bin/kafka-server-start.sh config/server-1.properties & $ bin/kafka-server-start.sh config/server-2.properties &
Yeni bir “topic” oluşturalım
$ bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 1 --topic my-replicated-topic
Oluşturduğumuz yeni “topic” sunuculara nasıl dağılmış acaba ?
$ bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic my-replicated-topic Topic:my-replicated-topic PartitionCount:1 ReplicationFactor:3 Configs: Topic: my-replicated-topic Partition: 0 Leader: 1 Replicas: 1,2,0 Isr: 1,2,0
En başta oluşturduğumuz “topic” nasılmış ?
$ bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic test Topic:test PartitionCount:1 ReplicationFactor:1 Configs: Topic: test Partition: 0 Leader: 0 Replicas: 0 Isr: 0
Nerelerde Kullanılabilir?
• Mesajlaşma Kuyruğu
• Websitesi Aktivite Takibi
• Sistem Metrikleri Toplanması
• Log Toplanması (Log Aggregation)
• Stream işleme (processing)
• Event Sourcing
• Commit Log (MySQL binary log gibi)
Kimler Kullanıyor?
Linkedin, Yahoo, Twitter, Netflix, Spotify, Pinterest, Airbnb, PayPal, vb… Detaylarına bu adresten ulaşabilirsiniz : https://cwiki.apache.org/confluence/display/KAFKA/Powered+By
Son olarak gayet güzel bir dokümantasyonu var : http://kafka.apache.org/documentation.html
Elasticsearch İle Metin İşleme Data Driven Kavramı ve II. Faz
Big Data teknolojilerinde şu anda çok popüler olan Kafka teknolojisini bizimle paylaştığın için çok teşekkürler.
Kafka’yı biz burda sanki bir db gibi mi kullanıyoruz? Streaming için ben cassandra kullandım ve insert-delete kısmında sıkıntı yaşamadım,ama burdada streaming işleme yada log toplama kullanılabilir denmiş.Loglarıda cassandraya anlık atıp analiz edebiliriz sonuçta.Tam olarak artısı ne anlayamadım?
Yazı içinde teşekkürler,güzel bir anlatım şekli.
Aslında anlık kelimesinden kastım real-time ya da near real-time diye tabir edilen gerçek zamanlı olarak, mesajlaşma yapısı ile mesaj okuma-yazma işlemi. Mesajlaşma sistemi olmasından dolayı da hiçbir mesaj sonsuza kadar saklanmıyor yani tam bir veritabanı diyemeyiz bence. Bahsettiğiniz konularda cassandra ya da benzeri bir araç tabiki kullanılabilir, ama Apache Kafka gibi anlık verinin çok yüksek adetlere ulaşabildiği (örneğin; saniyede 1 milyon mesaj) yapılarda, hem saklama için çok yüksek miktarda yer ayrılmıyor, hemde çok düşük response timelarla cevap alınabiliniyor. Ayrıca veritabanı dediğimiz şey birçok yeteneğe sahip (çoğu zaman kullanmasakta) bir şey ve bir çok farklı soruya cevap olma iddasında. Kafka ise belli ve kısıtlı bir soruna cevap olarak çıkmış durumda. Popülerlik artışı ile paralel olarakta birçok farklı toolda Kafka’yı destekliyor durumda.
okunan mesajların okunamaz hale gelmesini nasıl bir yöntem ile sağlıyoruz
Her consumer group içinde 1 kere okunur mesajlar, aynı mesajı birden fazla okumak isterseniz birden fazla consumer group tanımlarsınız.
Confluent kullandınızmı ? Tecrübelerinizi paylaşabilirmisiniz
“bin/zookeeper-server-start.sh config/zookeeper.properties” komutunu girince “Java HotSpot(TM) Server VM warning: G1 GC is disabled in this release.” böyle bir hata alıyorum ama işlemler devam ediyor. Gerçekten bir hata mı hataysa nasıl çözebilirim?