Amazon EMR
Amazon EMR Nedir?
Amazon Elastic MapReduce (EMR), büyük veri işlemeyi kolaylaştırmak amacıyla Amazon tarafından yönetilen, içerisinde Hadoop, Spark gibi açık kaynaklı büyük veri teknolojilerini içeren bir servistir. Aslında temelde AWS üzerinde Hadoop kümesi kurmak için tek tek sunucuları açmak, gerekli yazılımları yüklemek gibi işlemleri otomatik olarak yapmaktadır. Bu sayede tek tık ile bir kümeyi kurabileceğiniz gibi, işiniz bittiğinde de yine tek tık ile kümeyi silebilirsiniz. Yani, bu esneklik sayesinde çok daha büyük bir kümeyi veriyi işleyeceğiniz zaman yaratıp, veriyi işledikten sonra da kümeyi kapatarak kaynakları boşuna kullanmadan hesaplı ve hızlı bir şekilde sonuca ulaşabilirsiniz.
Neden Amazon EMR Kullanırım?
Büyük veri teknolojilerine yeni başlayanların en çok sıkıntı çektiği konulardan birisi uygun çalışma ortamına sahip olmamak. Sanal makineler yardımıyla kendi bilgisayarımızda bu teknolojileri öğrenmek mümkün, ancak öğrendiklerinizi gerçek hayatta uygulamak için gerçek bir kümeye sahip olmak malesef çok mümkün olmuyor. Amazon EMR bu problemi ortadan kaldırıyor. İstediğiniz kümeyi kurup, kurcalayıp, kullandığınız kadar ödeyebilirsiniz
POC aşamasında sunucu satın alıp kaynak ayırmak ile uğraşmak yerine, EMR ile POC çalışmanızı ya da demonuzu yapabilirsiniz.
Firmalar için ise, kullandığınız kadar ödemek gerçekten anlamlı. Örneğin günde bir kere çalışan ve TB’larca veriyi işlemeyi gerektiren batch bir iş için sürekli ayakta duracak bir Hadoop kümesine ihtiyacınız yok. Ücretlendirme kümeyi oluşturan EC2 sunucularının büyüklük ve sayısına göre yapılıyor. Ayrıca spot instance kullanma şansınız da var.
Spot instance kabaca, başkaları tarafından kiralanmış ancak boşta duran EC2 sunucularını normalden çok daha ucuza kullanmamızı sağlayan bir özellik. Bu avantaja rağmen ihtiyaç durumunda bu sunucuların sizden geri alınması dezavantajı var. Fakat büyük veri teknolojileri hata toleranslı olarak tasarlandıkları için, uygun tasarlanmış bir küme içerisindeki bazı sunucuların kapanması çalışan sistemi etkilemeyeceği için EMR ile spot instance kullanmak gerçekten iyi bir seçenek.
Bunun dışındaki diğer avantajları şöyle sıralayabiliriz:
- Her zaman güncel ve birbiriyle uyumlu yazılımları kullanma şansı
- EMR diğer AWS servisleri ile çok kolay entegre olabilir
- Çalışan EMR kümesi çalışma sırasında büyütülüp küçültülebilir
- EMR güvenliğinin IAM üzerinden yapılabilmesi, yani roller ve güvenlik gruplarıyla çalışabilmesi
- Encryption (şifreleme) desteği
- Mevcut izleme araçlarıyla entegrasyonu
- Yönetim kolaylığı, yani konsoldan, SDK üzerinden veya Web API üzerinden yönetim.
EMR Mimarisi
Amazon EMR hizmet mimarisi, her biri kümeye belirli yetenekler ve işlevler sağlayan birkaç katmandan oluşur.
Depolama (Storage): Verilerin işlenmesi amacıyla depolanacağı birden fazla depolama seçeneği mevcuttur.
- HDFS: EMR kümesi içerisindeki düğümler üzerinde kurulu olan HDFS bunlardan birisidir. Sunuculardan birisinde sorun oluşsa da HDFS üzerindeki veriler kaybolmaz. Ancak küme sonlandığında HDFS üzerindeki veriler de silinir.
- EMRFS: Bu dosya sistemiyle Amazon S3 üzerindeki veriler HDFS üzerindeymiş gibi kullanılabilir. Küme sonlansa dahi bu veriler saklanır.
- Local FS: Küme içerisindeki EC2 sunucularının kendi diskleridir. Eğer uygun şekilde ayarlanırsa bu veriler de küme sonlandığında saklanmaya devam eder.
Kaynak Yönetimi: Amazon EMR küme içerisindeki kaynakların yönetimi için Hadoop 2.0 ile gelen YARN bileşenini kullanır.
Veri İşleme Yazılımları: EMR kümesini ayağa kaldırırken yapacağınız seçeneklere göre Hadoop MapReduce veya Apache Spark çatılarını tercih edebilirsiniz. Ayrıca Hive, Pig, HBase, Presto, Zeppelin, Hue, Flink, vs gibi bir çok yazılımı dahil edebilirsiniz. Bunu da önceden hazırlanmış EMR sürümlerinden birini seçerek ya da küme ayağa kaldırırken özelleştirerek yapabilirsiniz.

Kümeler ve Düğümler
Amazon EMR servisinin temel bileşeni kümenin (cluster) kendisidir. Küme birden çok EC2 sunucusundan oluşur ve bu sunuculara düğüm (node) denir. Her bir düğümün bir rolü vardır. Bu roller:
Master node: Kümenin yönetilmesinden ve sağlığından sorumlu olan, diğer düğümlerin uyum içerisinde çalışmasını sağlayan, görev dağılımını yapan düğümdür.
Core node: Kendisine atanan görevleri çalıştıran ve HDFS dosya sisteminin bileşenlerini içeren işçi düğümdür.
Task node: Yalnızca kendine atanan görevleri çalıştıran, HDFS dosya sistemini barındırmayan, isteğe bağlı eklenen düğümlerdir.
Küme Yaşam Döngüsü
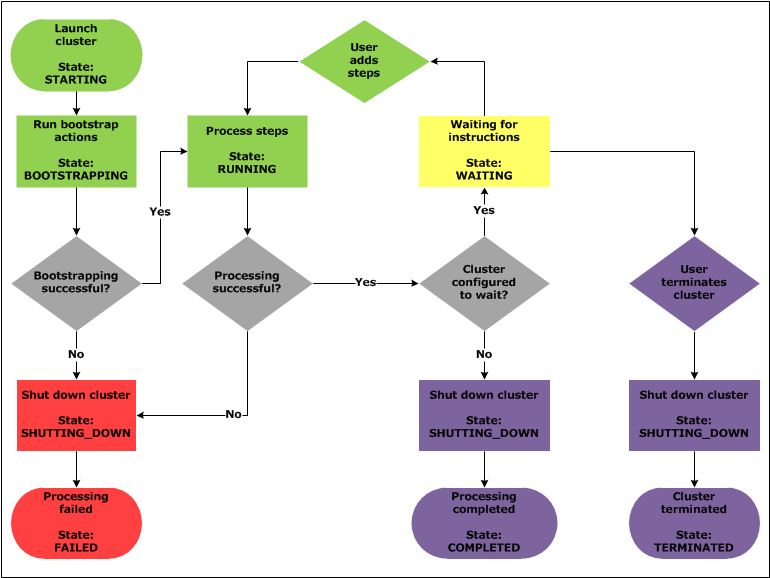
Bir EMR kümesi ayağa kaldırdığınızda küme belirli aşamalardan geçer:
- İlk ayağa kaldırma komutunu gönderdiğinizde küme STARTING aşamasındadır.
- İkinci aşamada eğer kullanıcı tanımlı bir komut verdiyseniz, örneğin farklı yazılımların kurulması gibi, bu sırada küme BOOTSTAPPING aşamasında olur.
- Bütün yazılımların kurulması tamamlandığında küme artık RUNNING aşamasına geçer. Küme bu aşamadayken kendine tanımlı görev adımları (steps) çalıştırır.
- Tüm görev adımlarının çalışması bittikten sonra küme WAITING aşamasında yeni görevleri bekler ya da SHUTTING_DOWN aşamasıyla kapanma aşamasına geçer. Bu durum otomatik sonlandırma (auto-terminate) seçeneği ile yönetilir.
- Eğer herhangi bir aşamada problem oluşursa küme TERMINATED_WITH_ERRORS aşaması ile sonlanır. Eğer herhangi bir problem olmaz ise COMPLETED aşaması ile küme sonlanmış olur.
Görev Adımlarının Çalışması
EMR kümesine bir veya birden fazla adımdan oluşan görevler verilebilir. Örneğin ilk olarak bir MR görevi çalışır, ardından MR sonucunda oluşan verileri bir Pig kodu işler, ondan sonra da Hive ile sorgulandıktan sonra sonuçları S3 üzerine yazan, yani birden fazla adımdan oluşan görev çalıştırılabilir.
Bu görev adımları çalıştırılırken de belirli aşamalardan geçer:
- Görev başlatılır
- Bütün adımlar PENDING aşamasına geçer
- İlk adım çalışmaya başladığında RUNNING aşamasına geçerken, diğer adımlar PENDING aşamasında beklerler
- Çalışan adım tamamlandığında COMPLETED aşamasına geçer
- Bir sonraki adım RUNNING aşamasına geçer
- Herhangi bir problem olursa en son çalışan aşama FAILED durumuna geçerken diğer adımlar CANCELLED aşamasına geçer.

Bir sonraki yazımızda Amazon EMR kümesi ayağa kaldırıp bir Spark uygulamasının nasıl çalıştırılacağını inceleyeceğiz.
Kaynak: https://docs.aws.amazon.com/emr/latest/ManagementGuide/emr-what-is-emr.html
AWS ile Big Data Amazon EMR ile Spark