Apache Spark
![]() Apache Spark bugünlerde ismini daha sık duymaya başladığımız, büyük veri işleme amaçlı bir diğer proje. Hadoop’tan 100 kat daha hızlı olmak gibi bir iddia ile birlikte, gelişmiş “Directed Acyclic Graph” motoruna sahip, Scala dili ile yazılmış ve bellek-içi (in-memory) veri işleme özellikleriyle bu iddiayı boşa çıkartmıyor gibi görünüyor. Özellikle Yapay Öğrenme algoritmalarının dağıtık implementasyonu konusunda Hadoop’tan daha performanslı olduğunu söyleyebiliriz. Öyle ki, Apache Mahout projesi bundan böyle Hadoop ile değil Spark üzerinde çalışacak şekilde geliştirilmeye etme kararı aldı.
Apache Spark bugünlerde ismini daha sık duymaya başladığımız, büyük veri işleme amaçlı bir diğer proje. Hadoop’tan 100 kat daha hızlı olmak gibi bir iddia ile birlikte, gelişmiş “Directed Acyclic Graph” motoruna sahip, Scala dili ile yazılmış ve bellek-içi (in-memory) veri işleme özellikleriyle bu iddiayı boşa çıkartmıyor gibi görünüyor. Özellikle Yapay Öğrenme algoritmalarının dağıtık implementasyonu konusunda Hadoop’tan daha performanslı olduğunu söyleyebiliriz. Öyle ki, Apache Mahout projesi bundan böyle Hadoop ile değil Spark üzerinde çalışacak şekilde geliştirilmeye etme kararı aldı.
Ancak şunu söylemeliyiz ki Spark Hadoop’un yerine geçecek bir teknoloji olmaktan ziyade, Hadoop ailesinin bir üyesi olup Hadoop’un zayıf kaldığı bazı konulardaki eksiklikleri giderecek gibi görünüyor. Hadoop binlerce sunucu üzerinde petabyte’larca veriyi stabil şekilde saklayıp analiz edebilecek şekilde tasarlanmışken, Spark göreceli olarak daha az miktarda veriyi özellikle in-memory olarak işlemek ve daha hızlı sonuç almak amacıyla tasarlanmış. Spark HDFS gibi herhangi bir storage çözümü sunmuyor ancak HDFS üzerinden okuma yazma yapabiliyor. Java ile Hadoop MapReduce uygulamaları geliştirmek çok low-level sayılırken, Spark ile bir uygulama geliştirmek çok daha kullanıcı dostu. Bu yüzden Spark’ı alet çantamızdaki farklı bir araç olarak görmemiz gerektiğini düşünüyorum.
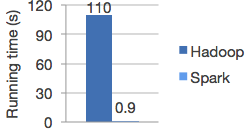
Logistic regression algoritmasının Hadoop ve Spark üzerinde çalıştırılması sonucu elde edilen performans örneklenmiş.
Spark kümesini standalone çalıştırmanın dışında Amazon EC2, Mesos ve YARN ile beraber çalıştırmanız mümkün. Dilerseniz test amaçlı olarak tek sunucuda lokal modunda da çalıştırabilirsiniz. Küme olarak çalıştırdığınızda bir master ve birden çok slave düğümü oluyor. Slave düğümlerinde kaç worker çalışacağını, bunların kaç cpu core ve ne kadar memory kullanacağını ayarlayamanız gerekiyor.
Uygulama geliştirme açısından Spark Scala’nın avantajlarını sonuna kadar kullanıyor. Örneğin artık “hello world” uygulaması yerine geçen “word count” uygulamasını Spark ile çok az bir kod parçası ile gerçekleştirebiliyoruz:
val file = spark.textFile("hdfs://...")
val counts = file.flatMap(line => line.split(" "))
.map(word => (word, 1))
.reduceByKey(_ + _)
counts.saveAsTextFile("hdfs://...")
Scala dışında Java ve Python dillerini de destekliyor. En güzel özelliklerinden birisi Spark’ın getirdiği soyutlama ile geliştirme yapmanın çok kolay hale gelmesi. Esnek Dağıtık Verisetleri ile (Resilient Distributed Dataset, kısaca RDD) veriyi sanki bir collection objesini işler gibi işlememiz sağlanmış. RDD’ler veri işlemeyi kolaylaştıracak map, filter, union, cartesian, join, groupByKey, sortByKey gibi birçok transformasyon metodunun yanı sıra, reduce, collect, count, distinct gibi aksiyon metodlarını içeriyor. Bir dosyayı veya bir collection objesini RDD’ye çevirip bu metodları ardışıl bir şekilde çağırarak veriyi işliyoruz. Transformasyon metodları lazy tasarlanmış, yani herhangi bir aksiyon metodu çağırılana kadar gerçekte bir işlem yapılmıyor. Spark uygulamalarını interaktif arayüzü (spark-shell) üzerinden test etmek mümkün. Örnek uygulamalara gözatabilirsiniz.
Java ile “word count” uygulaması örneği ise şöyle:
package com.devveri.spark;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;
import java.util.Arrays;
import java.util.regex.Pattern;
/**
* Created by hilter on 11/05/14.
*/
public class WordCount {
private static final String MASTER = "spark://localhost";
private static final Pattern SPACE = Pattern.compile(" ");
public static void main(String[] args) {
// create context
JavaSparkContext jsc = new JavaSparkContext(
MASTER,
"WordCount",
System.getenv("SPARK_HOME"),
JavaSparkContext.jarOfClass(WordCount.class)
);
// load file
JavaRDD<String> file = jsc.textFile("/Users/devveri/test.txt");
// split words
JavaRDD<String> words = file.flatMap(new FlatMapFunction<String, String>() {
public Iterable<String> call(String s) { return Arrays.asList(s.split(" ")); }
});
// create pairs
JavaPairRDD<String, Integer> pairs = words.map(new PairFunction<String, String, Integer>() {
public Tuple2<String, Integer> call(String s) { return new Tuple2<String, Integer>(s, 1); }
});
// count
JavaPairRDD<String, Integer> counts = pairs.reduceByKey(new Function2<Integer, Integer, Integer>() {
public Integer call(Integer a, Integer b) throws Exception { return a + b; }
});
// save result
counts.saveAsTextFile("/tmp/result");
}
}
Java 8’in yeni özelliklerinden faydalanmadığınız durumda Java ile Spark uygulaması geliştirmek böyle çirkin kodlar yazmanıza sebep oluyor, ancak çalışmasında herhangi bir performans farkı sözkonusu değil.
Örnekte ilk olarak bir JavaSparkContext objesi oluşturuyoruz. Sonrasında bir metin dosyasını yükleyip her bir satır bir String objesi olacak şekilde bir RDD oluşturuyoruz. Yüklenen her bir satırı flatMap metodu içerisinde yazdığımız fonksiyonda boşluklarından ayrılıyor, flatMap metodu da her bir elemanı birer satır haline dönüştürüyor. Kelime sayısını alabilmek için bu satırları map metoduna vererek [kelime, 1] formatında bir pair objesi haline getiriyoruz. Sonrasında reduceByKey metodu ile bu kelimelere karşılık gelen sayıları topluyoruz. En sonunda da sonucu bir metin dosyasına kaydediyoruz. Bütün bu işlemleri master düğümün arayüzünden takip edebilirsiniz.
Spark ile ilgili dikkat edilmesi gereken konulardan birisi Spark’ı hangi Hadoop sürümü ile çalıştırmak istediğiniz. Hadoop v1, v2, CDH3, CDH4, CDH5 gibi farklı Hadoop sürümlerine uygun sürümü bulup kurmanız ya da koddan derlemeniz gerekiyor. Aksi takdirde sorun yaşamanız çok muhtemel.
Bunların dışında Spark Streaming özelliği ile aslında Apache Storm projesinin sağladığı sürekli akan verileri anlık olarak işleyebilme özelliğini sağlıyor. Ayrıca Spark, Hive ile entegre olan dağıtık SQL motoru Apache Shark projesinde de altyapı sağlıyor. Son olarak MLlib isimli Yapay Öğrenme ve GraphX isimli çizge veritabanı projeleri de Spark çatısı altında toplanmış.
İlerleyen günlerde Spark daha fazla önümüze çıkacakmış gibi görünüyor.
ElasticSearch ve Pig Entegrasyonu Apache Nutch
Bildiğim kadarıyla, Spark Hadoop’un değil MapReduce’un alternatifi. Spark yine Hadoop HDFS üzerinde çalışacak farklı bir dağıtık programlama paradigması. Aynı şekilde Apache Giraph, Apache Hama projeleri de Hadoop HDFS üzerinde benzer nedenlerden ötürü MapReduce yerine BSP yaklaşımını tercih eden projeler.
Dediğiniz doğru ancak Spark severler “Spark yeni Hadoop” sloganını kullanıyorlar, ben de bunu kastetmiştim, teşekkürler.