Veri analizinde yeni alışkanlıklar
Veri işlemede kullanılan alet ve yöntemler baş döndürücü bir hızla gelişip değişiyor. Bunun sonucu olarak, eski adet ve alışkanlıklar ile devam ettirmeye çalıştığımız iş süreçlerinde çıkan sıkıntılar ve çıkmazlar sıradanlaştı. Bu yazıda, özellikle veri analizi konusunda çıkan sıkıntıları aşmak için alet kutumuza girmesi gerekli olan göreceli yeni üç aletten; data notebooks ve polyglot dillerden ve bu dünyanın getirdiği ek zorlukları aşmak için alet kutumuzda olması gereken docker container lardan bahsedeceğiz.
Çok dillilik (Polyglot)
Son zamanlarda büyük veri işleme ile ilgili isminden sıkça bahsettiğimiz birçok alet (tool), kendi dilleri ile birlikte geldi. Bunlara alana özel diller (domain specific languages – DSL) deniyor ve yazılım dilleri arasında geçiş yapılmayan tutucu eski günleri geride bıraktığımızı haber veriyorlar. Ayrıca, birçok yerde; R dili mi, Python mu tartışmaları yaşanırken, gerçek şu ki, bu iki dilin de aynı projede hatta aynı kişiler tarafından kullanılabildiği bir dönemi yaşadığımızı kabul etmemiz ve alışkanlıklarımızı buna göre değiştirmemizde fayda var. Polyglot olmanın normal olduğu bir dünyada yaşıyoruz artık.
Notebooks
Özellikle veri bilimi açısından bakıldığında, normal bir bilim insanının yaptığı gözlemleme, analiz ve sonuç çıkarma süreçlerinin, veriyi bilimsel olarak incelerken de geçerli olacağını düşünmek çok doğal olacaktır. Bu süreçte, gözlem ve analiz sonuçlarının veri ve bazı şekil ve grafiklerle zenginleştirilmiş halde olduğunu da eski örneklerinden (1) görmüşüzdür.
Alışkanlıkların değişmesi
Veri işleme, veriden sonuç çıkarma konusunda çalışan veri analisti, veri madencisi gibi ünvanlar ile çalışanlar için, bir dile bağlı olarak çalıştıkları dönemdeki alışkanlıklar ile devam etmeleri artık mümkün değil. Yeni veri bilimcileri için ise zaten doğal özelliklerden birisi.
Birbirinden bağımsız ve farklı birikimlerdeki akademik ve ticari dünyadan çok değerli insanlar teknolojinin getirdiği olanaklar sayesinde coğrafi yerden bağımsız olarak birlikte çalışıp üretebiliyorlar. Bunun sonucunda daha öncesinde hiç olmadığı kadar üretken bir yapı ortaya çıktı. Aynı problemi çözmeye odaklanmış çok sayıda grup bir araya gelip çeşitli çözümler üretiyorlar. Bu problemlerin hiç şüphesiz ki en çok ilgi çekenlerinden birisi, büyük verinin işlenmesi ve analiz edilmesidir.
Karmaşa
Değişik gruplar ve farklı birikimler, çözüme farklı yazılım dilleri ve aletleri olarak yansıyor. Bunun sonucunda pek çok alana özel dil geliştiriliyor. Bu dillerin belirli problemlerde kullanılması gerçekte daha iyi çözümler konusunda olanaklar sağlarken, çözüm ortamlarının karmaşasını da arttırıyor.
Daha önce veriyi belli dillerle işlemek alışkanlığına sahip birçok eski BT çalışanını ürküten bir durum bu. Öyle ya, RDBMS olan klasik bir ortamda çalışıyorsanız SQL biliyorsunuz, prosedürel algoritmalar için PL/SQL, T-SQL gibi dilleri öğrendiğinizde veri işlemenin birçok konusuna hakim oluyorsunuz. ETL aletlerini de kullanma beceriniz varsa, iş zekası katmanında kullanılan küp dilleri haricinde uçtan uca bir geliştirici, analist olabilirsiniz. Eğer veri madenciliğinin amiral gemisi SAS olan bir ortamda çalışıyorsanız, SQL yanında SAS programlama ve biraz da SAS Macro programlamayı bildiğinizde veriyi her türlü işleyebilirsiniz.
Bu az seslilikten çok sesliliğe geçişte, artık herkesin bildiği NoSQL veri tabanlarının neredeyse her birinin farklı bir DSL i olması eski dünya ve yenidünya sakinlerini birbirlerinden derin çizgilerle ayırıyor.
Uyum
Operasyondan sorumlu olanlar iyi bilirler, uyumluluk production sistemlerinde en büyük problemlerden birisidir. Bu nedenle bırakın farklı bir dilde çözüm üretmeyi, farklı bir versiyonda çözüm üretilmesi bile homurdanmalara yol açabilir. Bunun haklı sebepleri de var tabii ki, geliştirme ortamında çalışan bir kodun production da patladığı konusunda yaşanılan çoğu anlatılmamış kötü tecrübeler vardır.
Peki bu yeni dünyada, bir sürü belki de ismini bile duymadığımız dillerin kullanımı, operasyonel süreçleri nasıl etkiler? İşte bir sorun da buradan çıkıyor. Eski alışkanlıklar ile devam edildiğinde yenidünya çözümleri production tarafında iyiye gidişi desteklemez.
Dilemma
Peki bu paradoks gibi görünen durum nedir? Çok dillilik desteklenecek, ama aynı zamanda operasyonel işlemler de daha rahat yürüyecek. Bu noktada yenidünyanın yeni çözümü devreye giriyor. Şu anda iki farklı temsilcisi olan bu çözümün biz container tarafından bahsedeceğiz.
Containers
Uygulamaların production a kurulmadığını, geliştiricinin ortamının kontrollü olarak aynen kendi içlerinde paketlenerek çalıştırıldığını düşünelim. Teknik tabiri ile dilden bihaber (language agnostik) bir ortamdan bahsediyoruz. Her uygulama en uygun tool ve dil ne ise onunla geliştiriliyor.
Somutlaştırma
Buraya kadar genel hatları ile anlattığım süreci biraz somutlaştırmak için bir örnek üzerinde gideceğim. Veri bilimi konusunda da, kendimce çalışmalar yapan bir kişi olarak bir veri setinin alınması ve işlenmesi konusunda dilden bağımsız bir ortamda çalışma yapmak amacı ile ortaya çıkmış olan polyglot notebook lardan bazılarını inceleyip, bilinçli bir tercih yapmaya karar verdim. Mevcut seçenekler; Spark-notebook, Jupyter, Beaker-notebook, Zeppelin vb. Bunların her birini indirip makinamda kurulu olan sanal Ubuntu OS üzerinde kurup çalıştırmayı denedim. Yaklaşık iki gün boyunca indirme, kurma, ayarlamalar vb işlerle geçti. Yukarıda bahsettiğim, uyum problemi burada da çıktı. Örnek vermek gerekirse, scala 2.11 kurulu idi, ama kurduğum yazılım scala 2.10 istiyordu, Maven upgrade gerekti. Bir yerden sonra onu kur, bunu ayarla, sonuçta sadece spark-notebook u çalıştırabildim. Onda da istediğim şeyleri yapmada sıkıntı çıkınca, esas uğraşacağım işlere zaman ayıramadığımı fark ettim. Hedeften sapmıştım.
Evreka !
Bu süreçte eski dünyanın alışkanlıklarını terk etmek gerektiğine hükmettiğim yazımı ve katıldığım “Dockerize Yourself! Infinite Scalable Systems With Docker” da devveri.com yazarlarından Hüseyin Babal ın güzel uygulama+sunumunu hatırladım. Zaten Docker ile Mongo DB kullanımı ile ilgili bir yazısı da vardı sitemizde.
Değişim
Sonuçta, notebooklar ile ilgili çalışmayı docker container lar kullanarak yapmaya karar verdim. Docker ile ilgili dokümanları okumam ve ilgili yazılımları indirdikten sonra ortamı hazırlamam bir gün sürmedi. Akşamında beaker-notebook u kurup çalıştırmam birkaç dakikamı aldı. Bu işin güzel tarafı artık benzer kurulumları yapmak için baştaki eforu sarfetmem gerekmeyecek. Tabii uygulamaların network ayarlarının yapılması, uygulamalar arası veri alışverişi, port paylaşımları gibi teknik konularda uzmanlaşmak biraz daha vakit alacak ama ben yine de değişim isteyip, benim gibi nereden başlayacağını bilemeyenler için bir örnek sunmak istedim.
Örnek
Öncelikle Docker ın genel yapısından kısaca bahsedeyim. Docker container ile bir uygulamanın çalışması için gerekli olan dosya sistemi dahil her şeyi, bir pakette toplamayı sağlayan bir yapı sunuyor. Bu yapı iki türlü oluşturulabiliyor, daha önce oluşturulmuş paketlenmiş çalıştırılmaya hazır image dosyaları halinde veya installer ile. Image dosyaları ile daha önce var olan bir image de değişiklik yaparak saklayabiliyoruz. Installer ile özel bir script dili ile nelerin kurulacağını söylüyoruz. Bunun avantajı paylaşımı çok kolay oluyor ve şeffaf oluyor.
Bu oluşturulan image lar diğer insanlarla paylaşılmak istendiğinde bir repository ihtiyacı doğuyor. Bunu Docker şirketi sağlıyor. Bu repository den ücretsiz ve ücretli olmak üzere çeşitli yararlanma olanakları var.
Kurulum
Ben Windows olan bir makinaya kurulum yaptım. Kurulum detayları ile ilgili bilgilere buradan bakabilirsiniz. Docker Toolbox ile kurulum çok kolaylaştırılmış. Kurulum tamamlandıktan sonra ilk yapılan iş Docker Toolbox Terminal i tıklayıp açmak. Docker bir Linux uygulaması olduğu için Windows içinde Linux komutları yazmayı sağlayan bir emulator uygulaması. Linux ortamı olduğunu $ işareti ile anlıyorsunuz. Bu işaretin yanına tıklayıp Docker komutlarını yazabilir hale geliyoruz.
Her şeyin yolunda gittiğini anlamanız için
docker run hello-world
yazarak ilk uygulamanızı çalıştırabilirsiniz. Bu komut hello-world image ını local de arıyor, ilk seferinde bulamadığı için Docker Hub Repository ye gidip çekiyor. Dolayısı ile bu işlemin süresi, image ın büyüklüğü ile doğru orantılı oluyor. Sonrasında localde olduğu için hızla çalışıyor.
Bu hızlı girişten sonra gelelim esas amacımıza. Var olan Notebook lar içinden deneyip bakarak bir seçim yapmak istiyorduk. Bunu hızlı bir şekilde yapabilmek için bu notebookları kurulum ve ayarlamalar ile vakit kaybetmemek için Docker container ları kullanalım istiyoruz.
Burada biz bir tanesi için yapacağız, diğerlerini isteyenler kendileri yapabilirler. Ben daha önce görmediklerimden olduğu için aday olarak Beaker Notebook u seçtim. Genel olarak eski IPython notebook dan faydalanılmış nispeten yeni bir notebook ürünü. Başlama sayfasına (getting started) geldiğinizde sayfada uygulamayı kurmak için çeşitli alternatifler sunulmuş. Bu alternatiflerden Docker container ı seçtiğimizde docker hub daki açık repository e ilgili sayfaya ulaşıyoruz. Burada sayfanın sağında bulunan Docker pull commands kutusunun altında bulunan
docker pull beakernotebook/beaker
kopyalayıp, Docker Toolbox Terminal indeki $ işaretli komut satırına kopyalıyoruz. Enter a bastığımızda lokalimizde beakernotebook/beaker isimli image olmadığı için repository e bağlanıp çekmeye başlıyor. Tabii bu büyük bir imaj (4GB) olduğu için bekleme zamanı uzun oluyor.
Sonuçta her şey yolunda gittiğinde image lokalinize gelmiş olacak. Kontrol etmek için
Docker <command>
Komut ailesinden
docker image
komutunu kullanabiliriz.
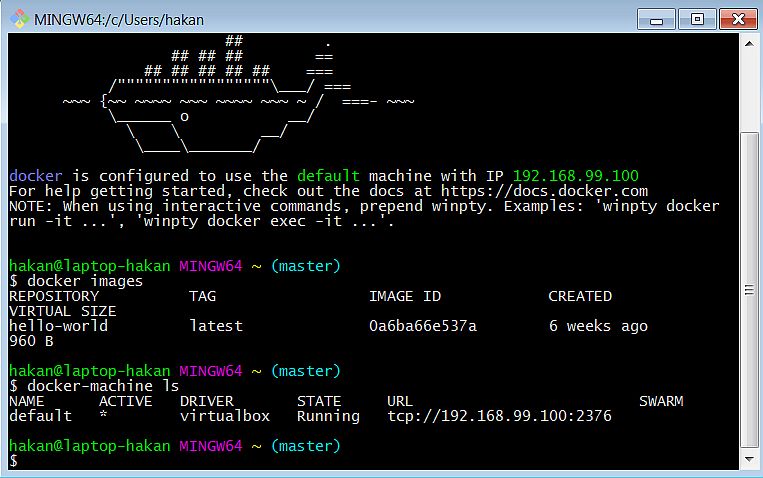
Docker makinası
Kısaca açıklayacak olursak, docker sanal bir makinanın özelliklerinden container bağımsız olanları ayrı bir şekilde çalıştırdığı için, birden fazla container için bir makine çalıştırarak sistem kaynaklarını ekonomik kullanmış oluyoruz. Aynı anda birden fazla makine çalıştırmak da mümkün. Bu aynı zamanda uygulamaların izalasyonunu sağlıyor. Artık containerdan istediğimiz sayıda çalıştırabiliriz.
Bu kısa açıklamalardan sonra beaker-notebook a dönersek;
$ docker run -p 8800:8800 -t beakernotebook/beaker
Komutu ile notebookumuzu çalıştırıyoruz. Çalıştırırken container ın kullandığı port ile localhost umuzun port ları arasında bir mapping yapmamız gerekiyor doğal olarak.
Connecting to https://29e59df53085:8800/
Submit this password: aKOMNCaRnIHUfnr
İlk çalıştırmada https üzerinden nasıl bağlanacağımız ve bağlantı sırasında sorulan şifreye verilecek rasgele atanmış şifremizi bir yere not ediyoruz. https adresi olarak yukarıdaki şekilde verdiğimiz URL i kullanmamız uygun olacak.
https://192.168.99.100:8800/
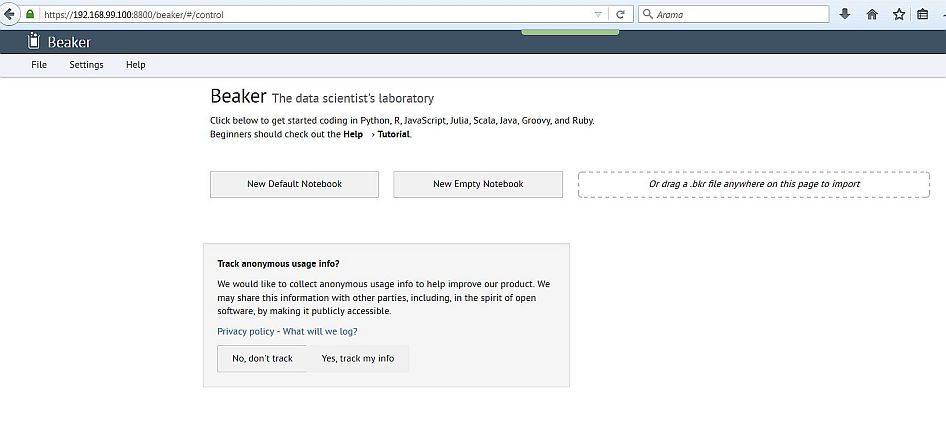
beaker notebook
Bu ekran geldiği an Notebooks dünyasına girmiş oluyoruz. İlk cümleye dikkat edersek
“Click below to get started coding in Python, R, JavaScript, Julia, Scala, Java, Groovy, and Ruby.”
Bu dünya polyglot bir dünya.
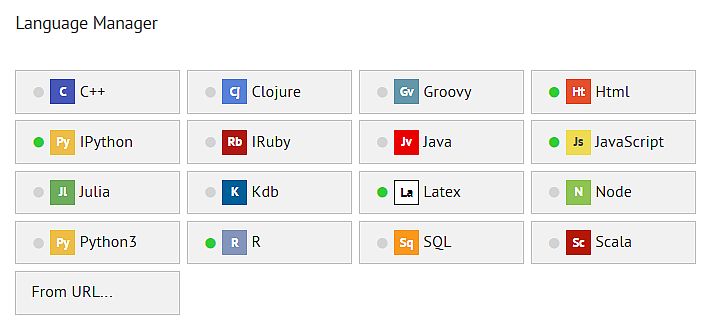
Polyglot notebooks
Bu üçleme; Docker, uygun bir data notebook ve polyglot diller yazının başında belirttiğimiz dünyanın üç temel unsuru.
Demokratik, çoğulcu bir dünya
Bu dünyada geliştiriciler, problem çözücüler probleme en uygun dili seçip, istedikleri versiyonu kullanma özgürlüğü kazanıyor. Python dünyasının versiyon 2 ve 3 arasındaki uyumsuzluklar bu dünyada problem olmaktan çıkıyor. En güzeli de genişleyebilirlik özelliği containerlar sayesinde çoklamanın kolay olması ile problem olmaktan çıkıyor.
Sonuç
Yazının başında belittiğimiz üç alet; data notebooks ve polyglot diller ve bu dünyanın getirdiği ek zorlukları aşmak için docker container lar kullanarak verimizi analiz edebileceğimiz bir ortamı kolayca kurduk. Belirli bir örneği başka bir yazıya bırakarak daha fazla uzamadan bu yazıyı sonlandıralım.
Daha İyi Bir Veri Bilimcisi Olmanız İçin 5 İnanılmaz Yol Kmeans ve Kmedoids Kümeleme