Apache Phoenix
 Bu yazımızda size Apache Phoenix projesini tanıtmayı amaçlıyoruz. Apache Phoenix, HBase üzerindeki verileri SQL arayüzü ile yüksek performanslı bir şekilde sorgulamamızı sağlayan bir proje. Shell üzerinden kullanabileceğimiz gibi, bir JDBC sürücüsüne de sahip.
Bu yazımızda size Apache Phoenix projesini tanıtmayı amaçlıyoruz. Apache Phoenix, HBase üzerindeki verileri SQL arayüzü ile yüksek performanslı bir şekilde sorgulamamızı sağlayan bir proje. Shell üzerinden kullanabileceğimiz gibi, bir JDBC sürücüsüne de sahip.
Phoenix, HBase’in özelliklerini çok iyi kullanarak yüksek performans sağlamayı amaçlıyor. SQL sorgularını HBase üzerinde scan yapacak şekilde derliyor, bu scan işlemlerinin başlangıç – bitişlerini ve paralel çalışmasını ayarlıyor, HBase’in performansını öne çıkartan coprocessor ve filter özelliklerini etkin bir şekilde kullanıyor. Bunlar dışında, secondary index desteği, istatistikler yardımıyla paralelleştirme ve optimizasyonlar da mevcut. Sadece okuma performansı değil, yazma performansını dağıtık bir şekilde sağlamak için salting özelliği de var. Bütün bunları yaparken de bize alışık olduğumuz SQL arayüzünü sunuyor. Bu özellikleriyle Phoenix oldukça kullanışlı bir araç olsa gerek.
Kurulum ve konfigürasyon
Phoenix kurulumu için HBase versiyonuna uygun bir sürüm seçmeniz gerekiyor. HBase 0.94.x için Phoenix 3.x, HBase 0.98.1 ve sonrası için Phoenix 4.x kullanmak gerekiyor.
Biz örneğimizi Cloudera Quickstart VM 5.1.0 üzerinde yapacağımız için Phoenix 4.x sürümünü indireceğiz. Phoenix içerisinde ayrıca MRv1 ve YARN için hadoop1 ve hadoop2 dizinleri bulunuyor. Uygun versiyon bizim için hadoop2 olacak.
Kurulum için Phoenix’i indirip açtıktan sonra, HBase kurulumunun yapıldığı yerdeki lib klasörü içerisine(bizim için /usr/lib/hbase/lib) Phoenix’in server jar dosyasını (phoenix-4.1.0-server-hadoop2.jar) sembolik linklememiz gerekiyor.
# ITU ve Bilken sunuculari hicbir zaman calismadigi icin mirror'dan indiriyoruz wget http://www.eu.apache.org/dist/phoenix/phoenix-4.1.0/bin/phoenix-4.1.0-bin.tar.gz # Kurulumu yapiyoruz cp phoenix-4.1.0-bin.tar.gz /opt/ cd /opt/ tar xvf phoenix-4.1.0-bin.tar.gz cd phoenix-4.1.0-bin/hadoop2/bin/ # hbase altina phoenix jar'ini linkliyoruz cd /usr/lib/hbase/lib/ ln -s /opt/phoenix-4.1.0-bin/hadoop2/phoenix-4.1.0-server-hadoop2.jar
Veri Hazırlığı
Phoenix ile HBase üzerinde daha önce varolan tablolar da tablo ya da view olarak tanıtılıp sorgulanabiliyor fakat biz burada her zaman kullandığımız NYSE veri setini biraz değiştirerek kullanacağız. Örnek dosyamıza bir ID alanı ekleyerek, tab ile ayrılmış dosyayı virgül ile ayrılmış hale getirmek için Linux’ün muhteşem komutlarından faydalanıyoruz:
# Dosyayi indir ve ac
wget https://s3.amazonaws.com/hw-sandbox/tutorial1/NYSE-2000-2001.tsv.gz
gunzip NYSE-2000-2001.tsv.gz
# Dosyaya satir numarasi ekle ve virgulle ayir
awk '{printf "%s,%s\n",NR,$0}' NYSE-2000-2001.tsv | sed '2,$y/\t/,/' > data.csv
Veri Yükleme
Phoenix bin klasörü altında işimize yarayacak birkaç komut var. Bunlardan birisi sqlline.py aracı. Bu araç ile herhangi bir JDBC desteği olan veritabanına bağlanabiliyoruz. Phoenix de JDBC driver’ına sahip olduğu için bu aracı kullanmamız mümkün. Parametre olarak HBase’in kullandığı Zookeeper adresini belirtmemiz gerekiyor. Örneğimizde localhost:2181/hbase adresini kullanarak bağlanıyoruz.
[root@quickstart bin]# ./sqlline.py localhost:2181/hbase Setting property: [isolation, TRANSACTION_READ_COMMITTED] issuing: !connect jdbc:phoenix:localhost:2181/hbase none none org.apache.phoenix.jdbc.PhoenixDriver Connecting to jdbc:phoenix:localhost:2181/hbase 14/10/26 14:27:21 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 14/10/26 14:27:23 WARN impl.MetricsConfig: Cannot locate configuration: tried hadoop-metrics2-phoenix.properties,hadoop-metrics2.properties Connected to: Phoenix (version 4.1) Driver: org.apache.phoenix.jdbc.PhoenixDriver (version 4.1) Autocommit status: true Transaction isolation: TRANSACTION_READ_COMMITTED Building list of tables and columns for tab-completion (set fastconnect to true to skip)... 68/68 (100%) Done Done sqlline version 1.1.2 0: jdbc:phoenix:localhost:2181/hbase>
NYSE tablomuzu oluşturmak için aşağıdaki SQL komutunu çağırıyoruz:
0: jdbc:phoenix:localhost:2181/hbase> CREATE TABLE NYSE (ID INTEGER NOT NULL PRIMARY KEY, EXCHANGE VARCHAR, STOCK_SYMBOL VARCHAR, STOCK_DATE VARCHAR, PRICE_OPEN DOUBLE, PRICE_HIGH DOUBLE, PRICE_LOW DOUBLE, PRICE_CLOSE DOUBLE, STOCK_VOLUME INTEGER, PRICE_ADJ_CLOSE DOUBLE); No rows affected (0.586 seconds)
Oluşan tabloları !tables komutu ile görebilirsiniz:
0: jdbc:phoenix:localhost:2181/hbase> !tables +------------+-------------+------------+------------+------------+------------+---------------------------+----------------+-------------+----------------+--------------+-------------+ | TABLE_CAT | TABLE_SCHEM | TABLE_NAME | TABLE_TYPE | REMARKS | TYPE_NAME | SELF_REFERENCING_COL_NAME | REF_GENERATION | INDEX_STATE | IMMUTABLE_ROWS | SALT_BUCKETS | MULTI_TENAN | +------------+-------------+------------+------------+------------+------------+---------------------------+----------------+-------------+----------------+--------------+-------------+ | null | SYSTEM | CATALOG | SYSTEM TABLE | null | null | null | null | null | false | null | false | | null | SYSTEM | SEQUENCE | SYSTEM TABLE | null | null | null | null | null | false | null | false | | null | null | NYSE | TABLE | null | null | null | null | null | false | null | false | +------------+-------------+------------+------------+------------+------------+---------------------------+----------------+-------------+----------------+--------------+-------------+ 0: jdbc:phoenix:localhost:2181/hbase>
Kullanabileceğimiz bir diğer araç olan psql.py yardımı ile CSV dosyaları Phoenix üzerinden HBase’e aktarmamız mümkün. Parametre olarak -t ile tablo ismini belirtiyoruz, Zookeeper adresini veriyoruz ve son olarak da içeri aktaracağımız CSV dosyasının adresini giriyoruz:
[root@quickstart bin]# ./psql.py -t NYSE localhost:2181/hbase /root/data.csv 14/10/26 15:05:45 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 14/10/26 15:05:46 WARN impl.MetricsConfig: Cannot locate configuration: tried hadoop-metrics2-phoenix.properties,hadoop-metrics2.properties csv columns from database. 14/10/26 15:05:50 ERROR util.CSVCommonsLoader: Error upserting record [1, exchange stock_symbol date stock_price_open stock_price_high stock_price_low stock_price_close stock_volume stock_price_adj_close]: 2 CSV Upsert complete. 812989 rows upserted Time: 259.044 sec(s)
Veri Sorgulama
Artık verisi de aktarılmış olan NYSE tablomuza örnek sorgular atabiliriz.
0: jdbc:phoenix:localhost:2181/hbase> SELECT COUNT(*) FROM NYSE; +------------+ | COUNT(1) | +------------+ | 812989 | +------------+ 1 row selected (12.164 seconds) 0: jdbc:phoenix:localhost:2181/hbase> SELECT STOCK_SYMBOL, AVG(PRICE_HIGH) AS AVG_HIGH FROM NYSE GROUP BY STOCK_SYMBOL ORDER BY AVG_HIGH DESC LIMIT 20; +--------------+------------+ | STOCK_SYMBOL | AVG_HIGH | +--------------+------------+ | WPO | 545.7559 | | GTC | 343.4477 | | WTM | 256.8117 | | MTB | 215.8028 | | MKL | 168.524 | | PC | 136.7031 | | IVV | 129.6019 | | JNPR | 123.9435 | | KYO | 121.965 | | IJK | 118.9919 | | UBS | 118.159 | | EFA | 117.7177 | | NVR | 115.8505 | | SPW | 115.6961 | | BCS | 115.2948 | | IBM | 110.9149 | | SNE | 108.451 | | IJR | 107.7051 | | BT | 107.5407 | | MMC | 106.4518 | +--------------+------------+ 20 rows selected (16.223 seconds)
Buradaki süreler sanal tek makinelik bir test ortamında olduğu için oldukça yüksek. Ancak gerçek bir kümede sorgular çok daha hızlı çalışacaktır. Buradaki amacımızın fonksiyonaliteyi test etmek olduğunu hatırlatmakta fayda var.
Phoenix kullanırken dikkat edilmesi gereken bir konu, tüm tablo ve kolon isimlerinin büyük harfli olması gerekliliği. Aksi durumda her bilginin “tırnak içerisinde” girilmesi gerekiyor. Biraz sinir bozucu bir durum.
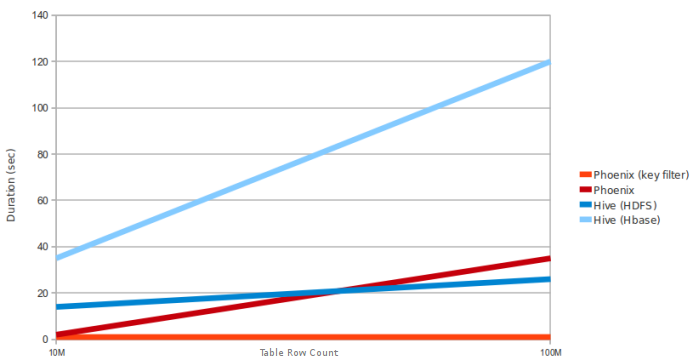
Daha önce Hive ile HBase entegrasyonu üzerine bir yazı hazırlamıştık. Phoenix-HBase ile Hive-HBase karşılaştırmalı performans grafiği ise aşağıdaki gibi:
Phoenix ile ilgili bilgilere buradan ulaşabilirsiniz.
Cloudera Hadoop Developer Eğitimi Cloudera Data Analyst Eğitimi Ankara
Elinize sağlık çok bilgilendirci bir makale olmuş. Benim de bir kaç küçük sorum olacaktı. Sensör verileri depolamak(4-5TB Boyut) ve sorgulamak için HBASE ve PHOENİX doğru bir platform mudur? Bir de .Net bir web arayüzünde verileri görüntülemek için. Microsoft – HDInsight depolama altyapısı mı yoksa fiziksel sunucularda Linux – Java Eclipse mi kullanmak daha doğru olur. Teşekkürler, iyi çalışmalar dilerim.
Sensör verileri için HBase + Phoenix’in uygun olabileceğini düşünüyorum. Verileri görüntülemek için varsa ODBC/JDBC driver kullanılabilir.