Apache Solr ile Otomatik Tamamlama
 Bu yazımızda Apache Solr kullanılarak otomatik tamamla ( bazen tavsiye olarak da isimlendiriliyor) nasıl yapılır onu anlatacağım.
Bu yazımızda Apache Solr kullanılarak otomatik tamamla ( bazen tavsiye olarak da isimlendiriliyor) nasıl yapılır onu anlatacağım.
Bu örneği olabildiğince genel hazırlamak için solr dağıtımını indirdiğimizde içinden çıkan varsayılan örnek üzerine inşa edeceğiz. java –jar start.jar ile çalıştırdığımız.
Schema.xml‘e yapılacak eklentiler:
İki tane yeni alan ve tip ekleyelim ve bu alanları copyField ile dolduralım.
<field name="subject_edgy_keyword" type="edgy_keyword" indexed="true" stored="false"/>
<field name="subject_edgy_ws" type="edgy_ws" indexed="true" stored="false"/>
<copyField source="subject" dest="subject_edgy_keyword"/>
<copyField source="subject" dest="subject_edgy_ws"/>
<fieldType name="edgy_keyword" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.KeywordTokenizerFactory" />
<filter class="solr.TrimFilterFactory" />
<filter class="solr.LowerCaseFilterFactory" />
<filter class="solr.EdgeNGramFilterFactory" minGramSize="1" maxGramSize="20" />
</analyzer>
<analyzer type="query">
<tokenizer class="solr.KeywordTokenizerFactory" />
<filter class="solr.LowerCaseFilterFactory" />
</analyzer>
</fieldType>
<fieldType name="edgy_ws" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.WhitespaceTokenizerFactory" />
<filter class="solr.LowerCaseFilterFactory" />
<filter class="solr.EdgeNGramFilterFactory" minGramSize="1" maxGramSize="20" />
</analyzer>
<analyzer type="query">
<tokenizer class="solr.WhitespaceTokenizerFactory" />
<filter class="solr.LowerCaseFilterFactory" />
</analyzer>
</fieldType>
Solrconfig.xml‘e yapılacak eklentiler: aşağıda gösterildiği tamamla isimli bir request handler kaydediyoruz.
<requestHandler name="/tamamla" default="false">
<lst name="defaults">
<str name="defType">dismax</str>
<str name="echoParams">none</str>
<str name="omitHeader">true</str>
<float name="tie">0.01</float>
<str name="qf">subject_edgy_ws^8 subject_edgy_keyword^4</str>
<str name="pf">subject_edgy_ws^2 subject_edgy_keyword^20</str>
<str name="fl">subject</str>
<int name="ps">0</int>
<int name="qs">0</int>
<str name="q.alt">*:*</str>
<str name="mm">100%</str>
<str name="version">2.2</str>
<int name="rows">10</int>
<int name="start">0</int>
</lst>
<arr name="components">
<str>query</str>
</arr>
</requestHandler>
Veri: Umuma açık bulunan MovieLens 10M verisini kullanacağız. ml-10m.zip dosyasını indirebilirsiniz.
Bu sıkıştırılmış klasörü açtığımızda içinden çıkan dosyalardan bize lazım olanı movies.dat dosyası. Bu dosyayı solr’a gönderebilmemiz için ufak bir iki değişiklik yapacağız. İndirdiğimiz dosyanın orijinal içeriği (10K satır) şu şekilde olacak:

Bu değişiklikler bir metin editöründe bul-ve değiştir işlemi olacak. Notepad++, TextWrangler gibi bir programla açıp şu iki işlemi sırasıyla yapalım:
1) Bütün | karakterlerini boşluk ile değiştirelim.
2) Bütün :: karakterlerini | ile değiştirelim.
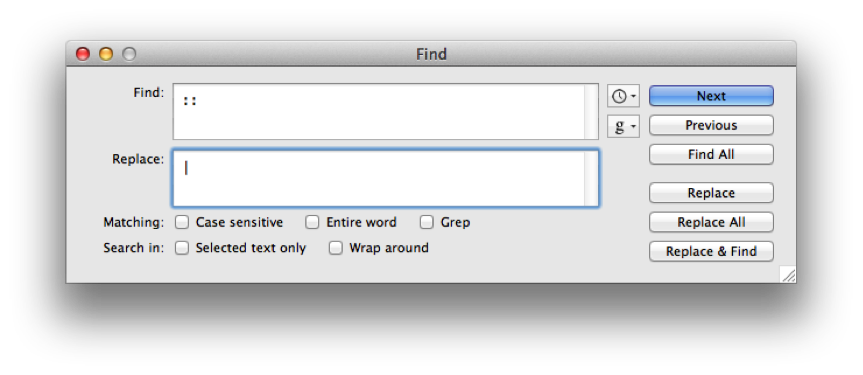
Dosyayı bu hali ile kaydedelim. Artık elimizde solr’a doğrudan beslenebilecek formatta getirdik. Curl programı ile bu dosyayı aşağıdaki komut ile indexleyelim:
curl "http://localhost:8983/solr/update?commit=true&fieldnames=id,subject,&separator=|&encapsulator=/" --data-binary @movies.dat -H 'Content-type:application/csv; charset=utf-8'
İşlemin sonunda söyle bir mesaj almamız lazım her şey yolunda gittiyse :
<?xml version="1.0" encoding="UTF-8"?>
<response>
<lst name="responseHeader">
<int name="status">0</int>
<int name="QTime">2404</int>
</lst>
</response>
Not: Windows işletim sistemlerinde curl programı hali hazırda gelmiyor. Ama Windows için sonradan kurmak mümkün. Ama ek kurulum yapmak istemezseniz, solr’un içinden (example/exampledocs dizini altında) post.jar kullanarak indeksleme için aşağıdaki komut satırını kullanabilirsiniz.
java -Durl="http://localhost:8983/solr/update?commit=true&fieldnames=id,subject,&separator=|&encapsulator=/ " -Dtype=text/csv -jar post.jar movies.dat
Her şey yolunda gittiyse, işlem sonunda siyah ekranda şuna benzer bir çıktı alırsınız:
SimplePostTool version 1.5 POSTing file movies.csv 1 files indexed. COMMITting Solr index changes to ... Time spent: 0:00:04.649
Arama: Kullanıcı tuşlara bastıkça, her tuşa basma sonunda /tamamla adresine tuşlanmış olan karakter serisini gönderiyoruz. Kullanıcı w tuşuna basmış olsun,
http://localhost:8983/solr/collection1/tamamla?q=w&wt=json&indent=true
gelen ilk üç sonuç şu şekilde olacaktır.
"subject": "Wild Wild West (1999)" "subject": "What Women Want (2000)" "subject": "When We Were Kings (1996)"

Yukardaki resimde (godf sorgusuna) dikkat ettiğiniz gibi ilk kelimesi godfather olanlar üstte, sonrasında ise ilk kelimesi olmadığı halde godfrey geçen film başlıkları da gelmiştir.
sex c sorgusuna ise gelen sonuçlar aşağıdaki gibidir.
http://localhost:8983/solr/collection1/tamamla?q=sex+c&wt=json

Eğer otomatik tamamlanın sıralamasına dahil etmek istediğiniz başka nümerik alanlarınız varsa onları da edismax’ın boost parametresi ile ekleyebilirsiniz. Örneğin bu örnekte filmlerin izlenme sayıları (view_count) elimizde olsaydı boost=sqrt(view_count) FunctionQuery olarak sıralamaya etki ettirebilirdik. Ya da son iki yılda çıkan filmleri üste getirmek için bq=year:[2013 TO 2014]^50 diye parametre ekleyebilirdik.
Kaynakça:
Auto-Suggest From Popular Queries Using EdgeNGrams
Different Ways To Make Auto Suggestions With Solr
Super flexible AutoComplete with Solr
Apache Pig – Domuzcuğun Hikayesi Büyük Veri İçindeki Nadir Görülen Olayların Keşfedilmesi